Ollama 사용 시작하기: 단계별 안내

작성자
- Zijian Yang (ORCID: 0009–0006–8301–7634)
소개
현재의 기술적인 환경에서 대규모 언어 모델(LLMs)은 인간 수준의 성능을 보여주며 텍스트 생성부터 코드 작성 및 언어 번역까지 다양한 작업에 사용되는 필수적인 도구가 되었습니다. 그러나 이러한 모델을 배포하고 실행하는 것은 일반적으로 상당한 자원과 전문 지식이 필요한데, 특히 로컬 환경에서는 그렇습니다. 여기에서 Ollama가 등장합니다.
Ollama란 무엇인가요?
Ollama는 대규모 언어 모델의 로컬 배포와 운영을 간소화하기 위해 설계된 오픈 소스 도구입니다. 적극적으로 유지보수되며 정기적으로 업데이트되며, 가볍고 쉽게 확장 가능한 프레임워크를 제공하여 개발자들이 손쉽게 로컬 머신에서 LLMs를 구축하고 관리할 수 있도록 합니다. 이는 복잡한 구성이나 외부 서버에 의존하지 않아도 되므로 다양한 애플리케이션에 이상적인 선택지가 됩니다.
Ollama의 주요 기능
Ollama를 사용하면 Llama 3, Gemma 및 Mistral과 같은 다양한 미리 구축된 모델에 액세스하고 실행하거나 자체 모델을 가져오고 사용자 정의할 수 있습니다. 이때 근본적인 구현의 복잡한 세부 사항에 대해 걱정할 필요가 없습니다. 이 도구는 모델 가중치, 구성 및 필요한 데이터 구성 요소를 포함하는 모델 파일을 정의함으로써 설정 프로세스를 간소화하며 복잡한 구성 파일이나 배포 절차가 필요하지 않습니다.
로컬 배포의 이점
Ollama를 사용하면 로컬 사용을 위해 오픈 소스 모델을 얻을 수 있습니다. 최고의 리포지토리에서 모델을 자동으로 가져와 컴퓨터에 전용 GPU가 있을 경우 GPU 가속을 원활하게 사용할 수 있습니다. 수동 구성이 필요하지 않습니다. 여러 대의 GPU를 사용하여 추론 속도를 가속화하고 리소스 집약적인 작업에 대한 성능을 향상시킬 수 있습니다. 또한 Ollama를 사용하여 로컬에서 LLMs를 실행하면 데이터가 컴퓨터를 벗어나지 않기 때문에 민감한 정보에 중요합니다.
기대할 수 있는 것들
본 기사는 Windows에 Ollama를 설치하고 사용하는 과정을 안내하며, 주요 기능을 소개하고, Llama 3와 같은 다중 모달 모델을 실행하고, CUDA 가속을 사용하며, 시스템 변수를 조정하고, GGUF 모델을로드하고, 모델 프롬프트를 사용자 정의하고, Docker를 통해 프론트 엔드 웹 사이트를 설치하여 챗봇을 더 우아하게 사용하는 방법을 소개합니다. 이는 큰 언어 모델의 능력을 탐색하고 활용하는 데 도움이 되는 방법을 보여줍니다. LLM을 빠르게 경험해보고자 하거나 로컬 환경에서 모델을 심층적으로 사용자 정의하고 실행해야 하는 경우, Ollama는 필요한 도구와 지침을 제공합니다.
Ollama의 다운로드 및 설치
Ollama의 설치 프로세스는 간단하며 macOS, Windows, Linux 및 Docker 환경을 포함한 다양한 운영 체제를 지원하여 넓은 사용성과 유연성을 보장합니다. 아래는 Windows 및 macOS 플랫폼용 설치 가이드입니다.
공식 웹사이트나 GitHub에서 설치 파일을 다운로드할 수 있습니다:
- Ollama 공식 웹사이트에서 다운로드
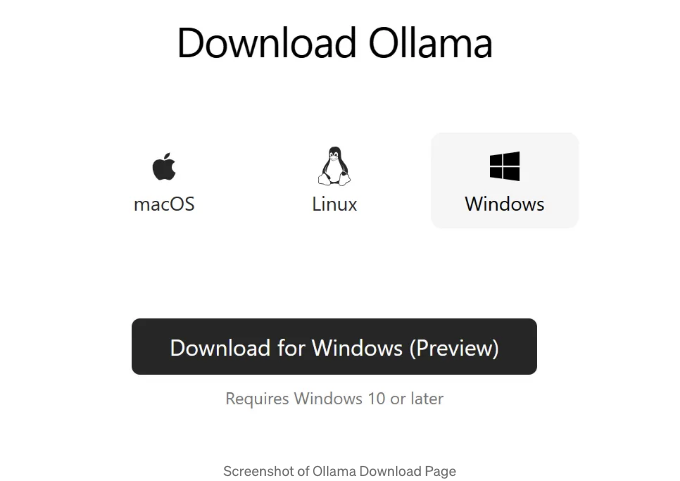
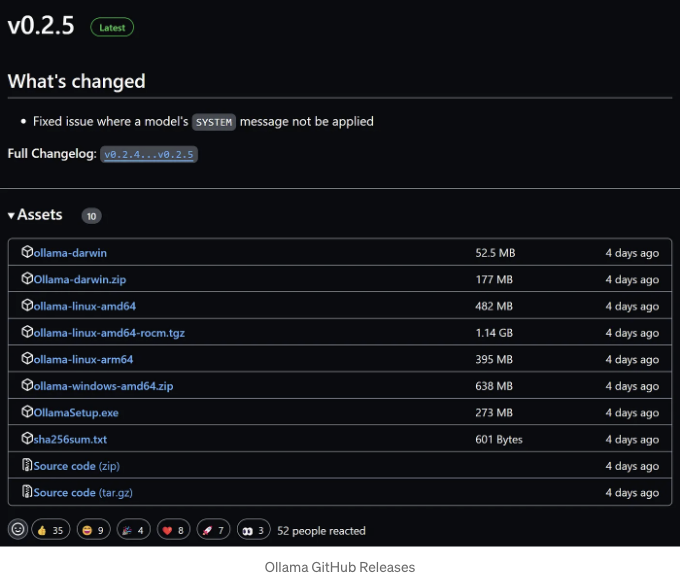
- Ollama GitHub 릴리스에서 다운로드
Windows에 Ollama 설치하기
여기서 Ollama 공식 웹사이트(https://ollama.com/download/OllamaSetup.exe)에서 설치 프로그램을 다운로드합니다.
설치 프로그램을 실행하고 설치를 클릭하세요.
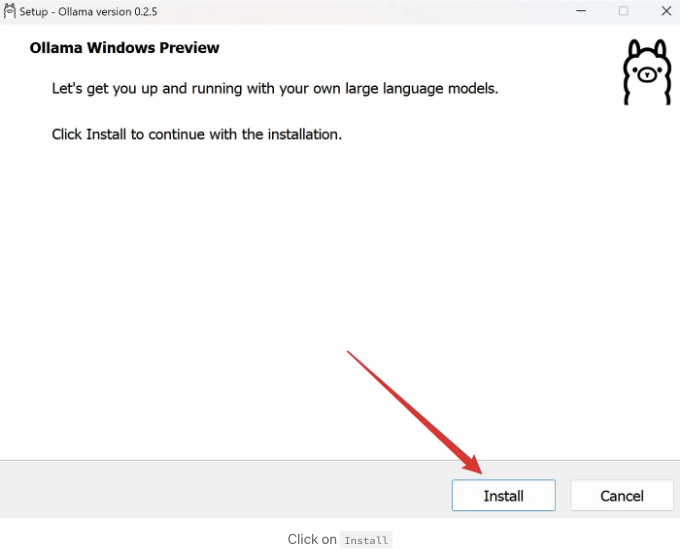
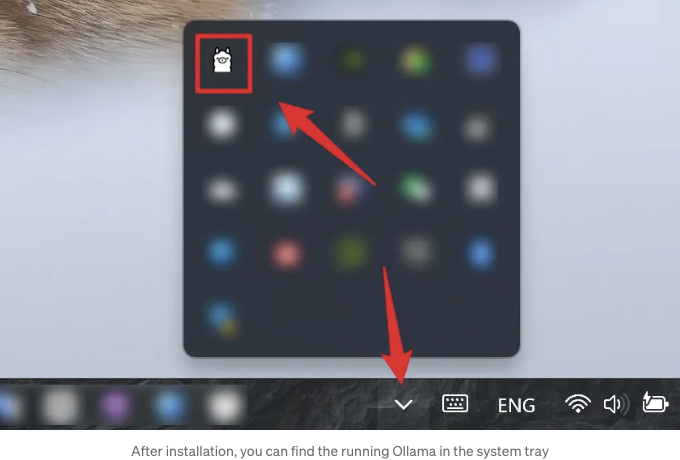
설치 프로그램은 자동으로 설치 작업을 수행하므로 조금만 기다려주세요. 설치 과정이 완료되면 설치 프로그램 창이 자동으로 닫힙니다. 아무 것도 보이지 않으면 걱정하지 마세요. Ollama가 지금은 백그라운드에서 실행되고 작업 표시줄 오른쪽에 시스템 트레이에서 찾을 수 있습니다.
macOS에서 Ollama 설치
Ollama의 macOS 설치 프로그램을 Ollama 공식 웹사이트에서 다운로드할 수 있어요. 이와 다른 플랫폼에 대한 상세한 설치 지침은 여기에 다루지 않을 거예요.
Linux에 Ollama 설치하기
curl -fsSL https://ollama.com/install.sh | sh
더 자세한 내용은 공식 매뉴얼을 참조하시면 됩니다: 수동 설치 지침
도커를 통해 Ollama 설치하기
공식 Ollama 도커 이미지 ollama/ollama는 Docker Hub에서 사용할 수 있습니다.
docker pull ollama/ollama
Ollama 사용 방법
이 게시물에서는 Windows 플랫폼을 사용하여 Ollama를 사용하는 방법을 소개합니다. macOS 및 기타 플랫폼에서의 사용법도 비슷합니다.
모델 저장 위치 및 환경 변수 사용자 정의하기 (선택 사항)
이 섹션은 필수가 아닙니다. 이 부분을 건너 뛰어도 Ollama를 사용하는 데 영향을 미치지 않습니다.
Ollama를 사용하기 전에 시스템 드라이브 또는 파티션(C:)에 여유 공간이 제한적이거나 파일을 다른 드라이브나 파티션에 저장하는 것을 선호하는 경우, Ollama 모델의 기본 저장 위치를 변경해야 합니다. 기본적으로 Ollama는 다운로드된 모델을 C:\Users%username%.ollama\models에 저장하며, 모델은 몇 기가바이트에 달할 수 있으므로 이는 시스템 드라이브의 여유 공간을 빠르게 감소시키며 시스템 성능에 영향을 줄 수 있습니다.
마찬가지로 macOS의 경우 모델의 기본 저장 위치는 ~/.ollama/models이며, Linux의 경우 /usr/share/ollama/.ollama/models입니다.
다른 디렉토리를 사용해야 하는 경우 선택한 디렉토리로 환경 변수 OLLAMA_MODELS를 설정해야 합니다. 다음은 설정 방법입니다:
Windows의 경우 Ollama는 사용자 및 시스템 환경 변수를 상속합니다.
- 처음으로 작업 표시줄에서 클릭하여 Ollama를 종료하세요.
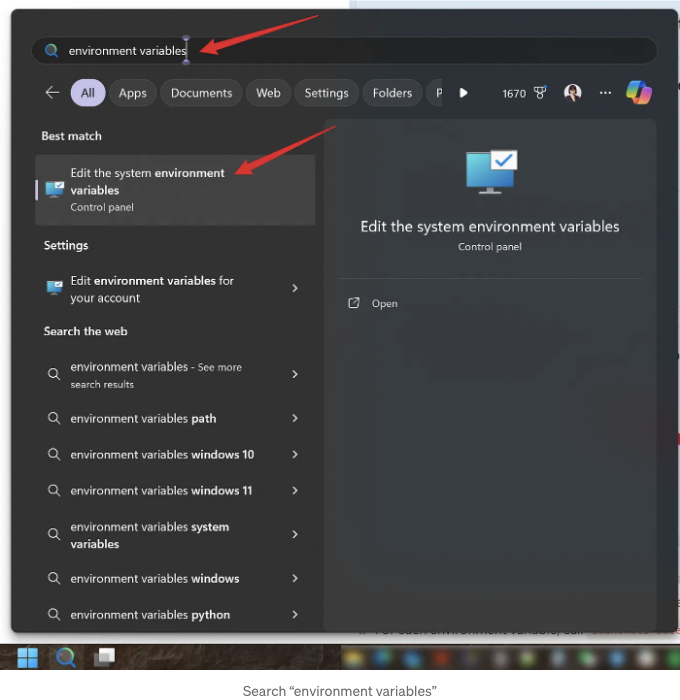
- 설정(Windows 11) 또는 제어판(Windows 10) 애플리케이션을 시작하고 환경 변수를 검색하세요.
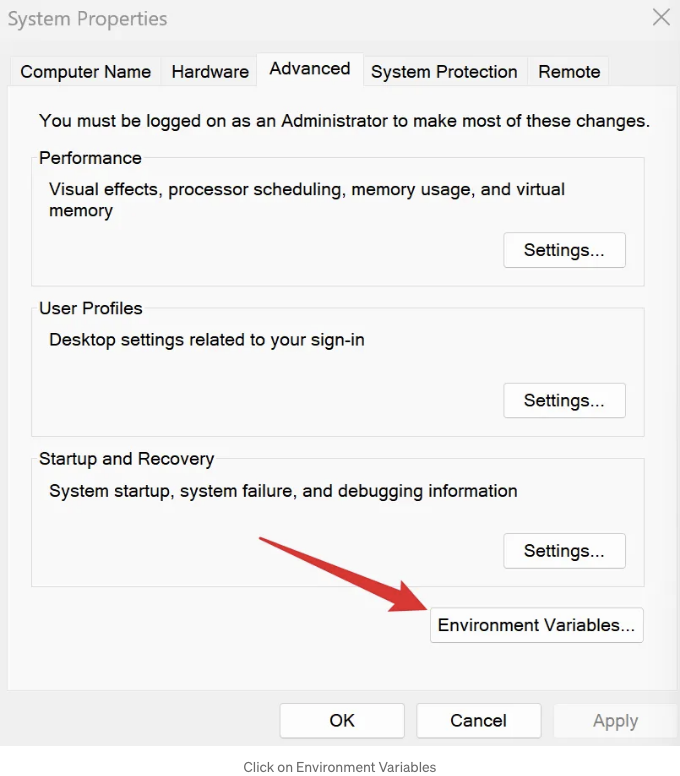
- 시스템 환경 변수 편집을 클릭하세요.
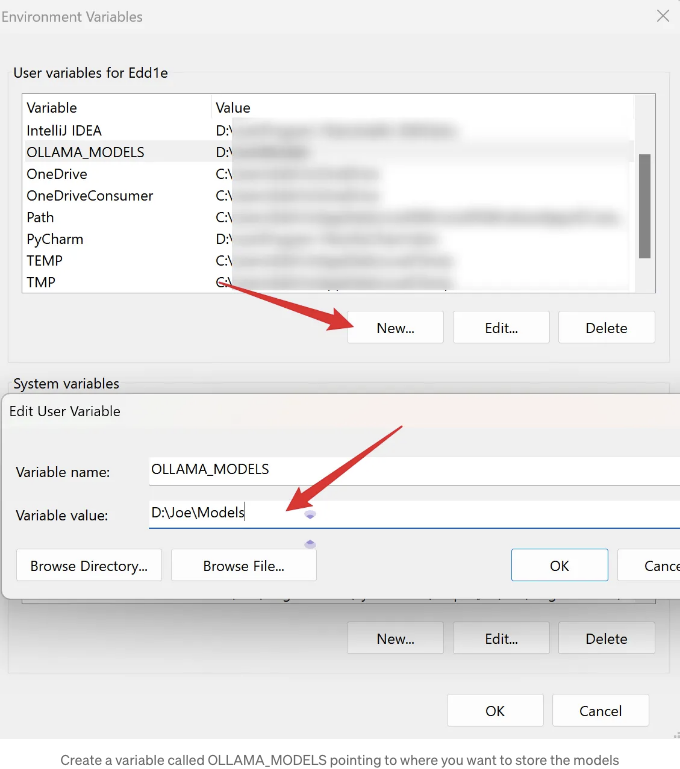
- 모델을 저장할 위치를 가리키는 OLLAMA_MODELS라는 변수를 만드세요.
- 저장하려면 확인/적용을 클릭하세요.
- Windows 시작 메뉴에서 Ollama 애플리케이션을 시작하세요.
만약 Ollama를 macOS 애플리케이션으로 실행한다면, 환경 변수를 설정할 때 launchctl을 사용해야 합니다:
- 각 환경 변수에 대해 launchctl setenv를 호출하세요.
launchctl setenv OLLAMA_MODELS /경로/
- Ollama 애플리케이션을 다시 시작하세요.
위 설정을 적용한 후 Ollama를 사용하여 모델을 끌어오면 사용자 정의 위치에 저장됩니다.
다른 일반적으로 사용되는 시스템 환경 변수는 필요에 따라 설정할 수 있습니다 (옵션):
- OLLAMA_HOST: Ollama 서비스가 수신 대기하는 네트워크 주소입니다. 기본값은 127.0.0.1입니다. 다른 컴퓨터(예: 로컬 네트워크의 컴퓨터)에서 Ollama에 액세스하려면 0.0.0.0으로 설정하여 다른 네트워크에서 액세스를 허용할 수 있습니다.
- OLLAMA_PORT: Ollama 서비스의 기본 포트입니다. 기본값은 11434입니다. 포트 충돌이 발생하면 다른 포트(예: 8080)로 변경할 수 있습니다.
- OLLAMA_ORIGINS: HTTP 클라이언트 요청 원본의 쉼표로 구분된 목록입니다. 엄격한 요구 사항 없이 로컬에서 사용하는 경우, 제한 없음을 나타내기 위해 별표(*)로 설정할 수 있습니다.
- OLLAMA_KEEP_ALIVE: 대형 모델이 메모리에 유지되는 기간입니다. 기본값은 5분(5m)입니다. 예를 들어, 300과 같이 숫자만 있는 경우 300초를 의미하며, 0은 요청 처리 후 모델이 즉시 언로드되고, 음수는 무제한으로 로드된 상태를 유지함을 의미합니다. 액세스 속도를 개선하기 위해 모델을 24시간 동안 메모리에 유지하려면 24시간으로 설정할 수 있습니다.
- OLLAMA_NUM_PARALLEL: 동시 요청 핸들러 수입니다. 기본값은 1로 요청이 직렬로 처리됩니다. 실제 요구 사항에 따라 이 값을 조정하세요.
- OLLAMA_MAX_QUEUE: 요청 큐의 길이입니다. 기본값은 512입니다. 이 길이를 초과하는 요청은 삭제됩니다. 상황에 맞게 이 설정을 조정하세요.
- OLLAMA_DEBUG: 디버그 로그를 출력하는 플래그입니다. 자세한 로그 정보를 출력하려면 1로 설정하면 문제 해결에 유용합니다.
- OLLAMA_MAX_LOADED_MODELS: 동시에 메모리에 로드할 수 있는 모델의 최대 수입니다. 기본값은 1로 한 번에 하나의 모델만 메모리에 로드할 수 있습니다.
빠른 시작: Llama 3 사용해보기
메타의 최신 오픈 소스 모델, 람마 3 8B를 빠르게 경험해 볼 수 있어요. ollama run llama3 명령어를 사용해서 바로 체험할 수 있어요. 먼저 명령줄 창을 열어주세요. (이 문서에서 언급된 명령은 cmd, PowerShell 또는 Windows Terminal을 사용해서 실행할 수 있어요.) 그리고 ollama run llama3를 입력하면 모델을 다운로드할 수 있어요. (다른 모델을 경험하고 싶다면, 후술된 "모델 라이브러리" 섹션을 참고하여 다른 모델과 해당 명령어 목록을 확인하거나, 사용자 지정 GGUF 모델을 로드하려면 "GGUF에서 가져오기" 섹션을 따를 수 있어요.)
C:\Users\Edd1e>ollama run llama3
manifest를 가져오는 중
6a0746a1ec1a 다운로드 중... 100% 완료 ▕████████████████████████████████████████████████████████▏ 4.7 GB
4fa551d4f938 다운로드 중... 100% 완료 ▕████████████████████████████████████████████████████████▏ 12 KB
8ab4849b038c 다운로드 중... 100% 완료 ▕████████████████████████████████████████████████████████▏ 254 B
577073ffcc6c 다운로드 중... 100% 완료 ▕████████████████████████████████████████████████████████▏ 110 B
3f8eb4da87fa 다운로드 중... 100% 완료 ▕████████████████████████████████████████████████████████▏ 485 B
sha256 다이제스트 확인 중
manifest 작성 중
사용되지 않는 레이어 제거 중
성공
>>> 메시지를 전송해보세요 (도움말을 보려면 /?)
모델을 다운로드 받은 후, Llama 3 8B를 사용할 수 있어요. 명령줄에서 모델에 대화 내용을 바로 전송할 수 있어요.
예를 들어, 먼저 모델에게 자신이 누군지 물어볼 수 있어요:
>>> 당신은 누구신가요?
저는 Meta AI가 개발한 LLaMA라는 AI 어시스턴트입니다. 대화식 방식으로 인간의 입력을 이해하고 응답할 수 있는 컴퓨터 프로그램입니다. 인간이 아니라 대화를 시뮬레이션하고 질문에 응답하는 데 최선을 다하기 위해 설계된 프로그램입니다.
제 주요 기능은 과학, 역사, 연예 및 문화 등 다양한 주제에 대한 정보를 제공하고 질문에 답하는 것입니다. 자연스럽고 종종 인간이 쓴 것과 구분하기 어려운 텍스트 응답을 생성할 수 있습니다. 다양한 소스에서 텍스트 데이터 세트를 사용하여 훈련되었습니다. 이 훈련을 통해 언어의 패턴과 관계를 인식하고 사용자 입력에 대해 이해하고 응답할 수 있습니다.
제가 할 수 있는 일의 몇 가지 예는 다음과 같습니다:
1. 질문에 답변하기: 과학, 역사, 연예 및 문화 등 다양한 주제에 대한 정보를 제공할 수 있습니다.
2. 텍스트 생성: 프롬프트나 주제를 기반으로 원래의 텍스트를 작성할 수 있습니다.
3. 내용 요약: 긴 텍스트를 더 짧고 이해하기 쉬운 버전으로 요약할 수 있습니다.
4. 제안하기: 여행지, 레스토랑 또는 읽을 책 등의 아이디어나 옵션을 제안할 수 있습니다.
사용자 상호 작용을 기반으로 응답을 지속적으로 학습하고 개선하고 있으므로 실수를 한 경우 양해 부탁드립니다!
Llama 3이 정보와 기능을 명확하게 소개하고 있습니다. 두 가지 간단한 질문을 하면서 계속해서 테스트를 진행할 수 있습니다:
>>> 방 안에 책이 1000권 있고, 저는 2권을 읽었습니다. 방 안에 남아 있는 책은 몇 권인가요? 간결하게 답하세요
998권.
>>> 왜요?
2권을 읽어서 방 안에 남아있는 책 수는 1000 - 2 = 998권입니다.
>>> 9.11과 9.2 중 어느 것이 더 크죠?
9.2가 9.11보다 큽니다.
2권을 읽었다고 해서 그 2권이 방을 떠났다는 것은 아닙니다. Llama 3는 간단한 논리적 질문에 대답할 때 환각을 유발한다는 것이 분명하며, 여러 가지 새로운 대화 테스트 후에도 일관적으로 잘못된 답변을 제공합니다. 따라서 모델이 생성한 내용은 오류가 있을 가능성이 높으며 완전히 신뢰해서는 안 됩니다.
Ollama Model Library
다른 모델을 시도해보고 싶다면 Ollama에서 제공하는 모델 목록에 액세스할 수 있습니다. https://ollama.com/library.
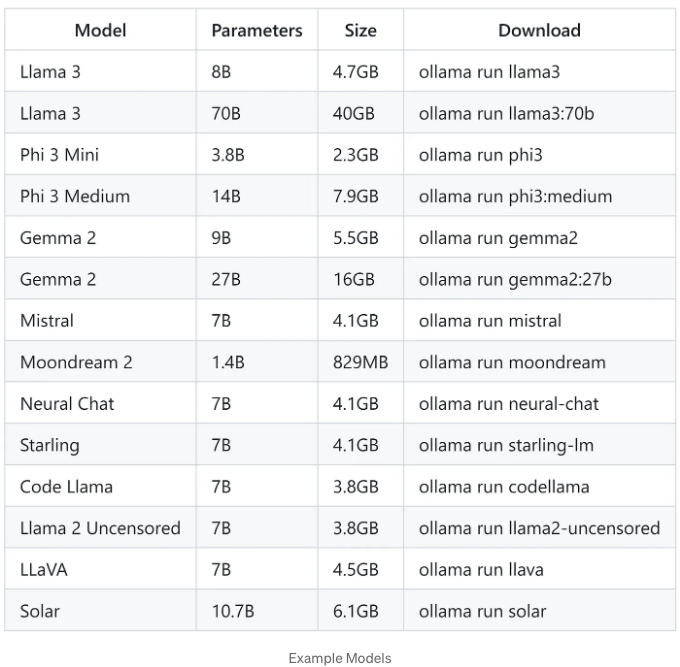
다음은 다운로드할 수 있는 몇 가지 예제 모델입니다:
작업 명령어
모델을 실행하기 전에, Ollama가 다음 명령어를 가지고 있음을 알아두어야 합니다. 이 명령어들은 Ollama의 다양한 기능을 활용하기 위해 명령 줄에서 실행할 수 있습니다:
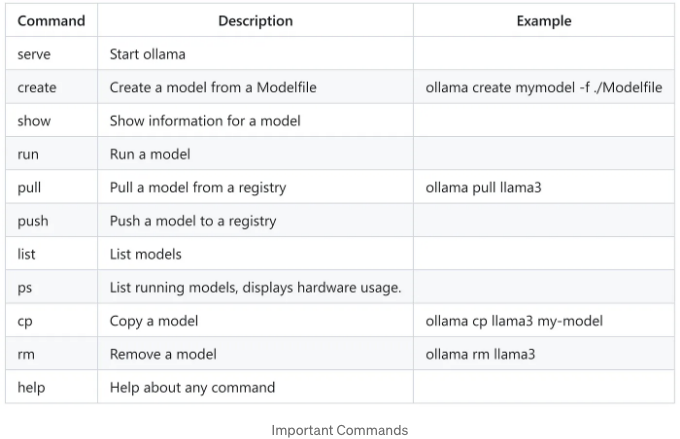
특정 명령어에 대한 도움말 콘텐츠를 받고 싶다면, ollama [command] --help와 같이 입력하여 해당 명령어에 대한 보다 자세한 사용 정보를 얻을 수 있습니다. 예를 들어, ollama run --help를 입력하면 다음과 같은 내용이 표시됩니다:
C:\Users\Edd1e>ollama run --help
Run a model
사용법:
ollama run MODEL [PROMPT] [flags]
플래그:
--format string 응답 형식 (예: json)
-h, --help run 명령어 도움말
--insecure 보안이 취약한 레지스트리 사용
--keepalive string 모델 로드를 유지할 시간(예: 5m)
--nowordwrap 단어를 자동으로 다음 줄로 개행하지 않음
--verbose 응답 시간 표시
환경 변수:
OLLAMA_HOST ollama 서버의 IP 주소 (기본값 127.0.0.1:11434)
OLLAMA_NOHISTORY readline 히스토리를 유지하지 않음
모델이 실행 중일 때 다음 작업을 수행할 수 있습니다:
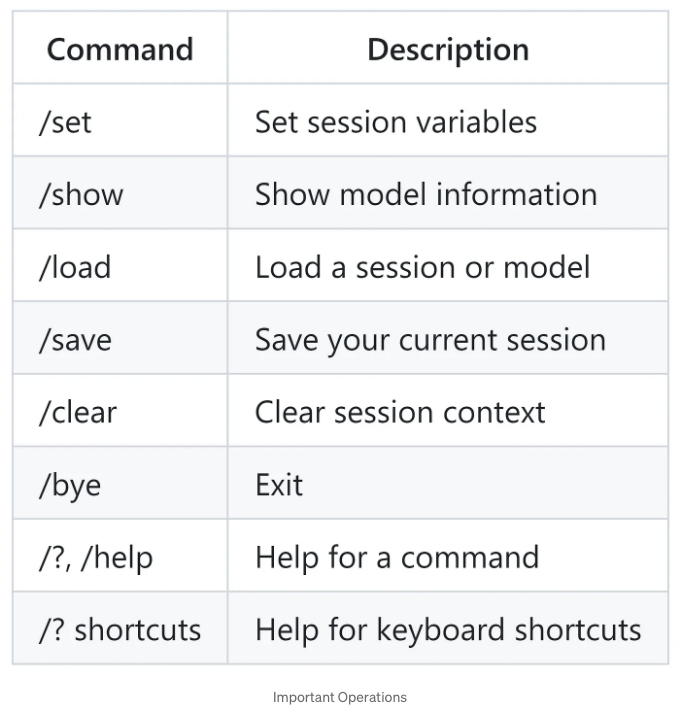
또한, 다음과 같이 삼중 따옴표(")를 사용하여 여러 줄 메시지를 시작할 수 있습니다. 예를 들어:
>>> """안녕하세요,
... 세상아!
... """
저는 콘솔에 유명한 "Hello, world!" 메시지를 출력하는 기본 프로그램입니다.
몇 가지 다중 모달 모델의 기능도 활용할 수 있어요. 이미지를 모델이 인식하도록 할 수도 있어요. 예를 들어, DALLE-3로 생성된 이미지를 인식하기 위해 LLaVA 모델을 사용할 수 있어요. 그냥 이미지 경로를 프롬프트에 포함시키면 되죠:
ollama run llava
>>> 이 이미지에 뭐가 있을까요? "D:\Joe\Downloads\test.png"
이미지 'D:\Joe\Downloads\test.png'이 추가되었습니다.
이 이미지는 두 명의 사람이 셀카를 찍고 있는 것을 보여줍니다. 그들은 얼굴 마스크를 썼으며, 실외 환경에서 촬영된 것으로 보입니다. 한 사람은 카메라 앱이 열린 핸드폰을 들고 있고, 다른 한 사람은 첫 번째 사람의 어깨를 감싸았습니다. 두 사람은 캐주얼하게 차려입었으며, 우산이나 폰초처럼 보이는 것을 착용하고 있어요. 사진은 맑은 하늘과 자연 환경을 통해 여행이나 탐험의 순간을 담고 있습니다."

볼 수 있듯이, 모델은 이미지의 세부 사항을 정확하게 설명했고, 거의 완벽하게 이미지를 생성하기 위해 사용한 프롬프트를 재현했어요.
로그 보기
가끔 Ollama가 예상대로 작동하지 않을 수 있습니다. 무슨 일이 있었는지 알아내는 가장 좋은 방법 중 하나는 로그를 확인하는 것입니다.
Windows에서 Ollama를 실행할 때 확인할 수 있는 여러 위치가 있습니다. Win+R을 눌러 파일 탐색기를 열고 다음 명령어를 입력해보세요:
explorer %LOCALAPPDATA%\\Ollama # 로그 보기
explorer %LOCALAPPDATA%\\Programs\\Ollama # 바이너리 검색 (설치 프로그램이 사용자의 PATH에 이를 추가함)
explorer %HOMEPATH%\\.ollama # 모델 및 구성 저장 위치 검색
explorer %TEMP% # 일시적 실행 파일은 하나 이상의 ollama* 디렉토리에 저장됩니다
맥에서는 다음 명령어를 실행하여 로그를 찾을 수 있어요:
cat ~/.ollama/logs/server.log
필요하다면 더 자세한 로그 정보를 얻기 위해 환경 변수 OLLAMA_DEBUG를 "1"로 설정할 수 있어요.
GPU 가속 사용하기: CUDA Toolkit 설치하기 (선택 사항)
Llama 3 8B와 같은 작은 모델의 경우 CPU 또는 통합 그래픽을 사용하는 것이 잘 작동할 수 있습니다. 그러나 만약 컴퓨터가 Nvidia 독립 GPU를 보유하고 있고 더 큰 모델을 실행하거나 더 빠른 응답 시간을 원한다면 CUDA Toolkit을 설치하여 독립 GPU를 더 잘 활용해야 합니다.
참고: 이 단계는 계산 능력이 5.0이상인 Nvidia GPU에만 적용됩니다.
AMD GPU를 사용 중이라면, Ollama가 지원하는 장치 목록을 확인하여 귀하의 그래픽 카드가 Ollama에서 지원되는지 확인할 수 있습니다. 그러나 CUDA Toolkit은 Nvidia GPU에만 적용되므로 AMD GPU 사용자들은 걱정할 필요가 없습니다 - 아무런 장단점이 없습니다.
Ollama는 다음 AMD GPU를 지원합니다:

Next, Nvidia GPU 사용자는 그래픽 카드가 지원되는지 확인하기 위해 컴퓨트 호환성을 확인해야 합니다: Nvidia CUDA GPUs
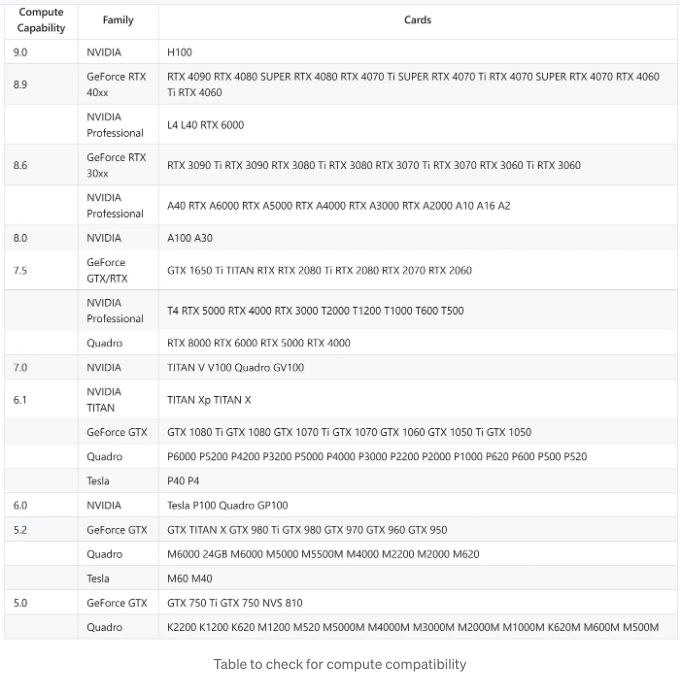
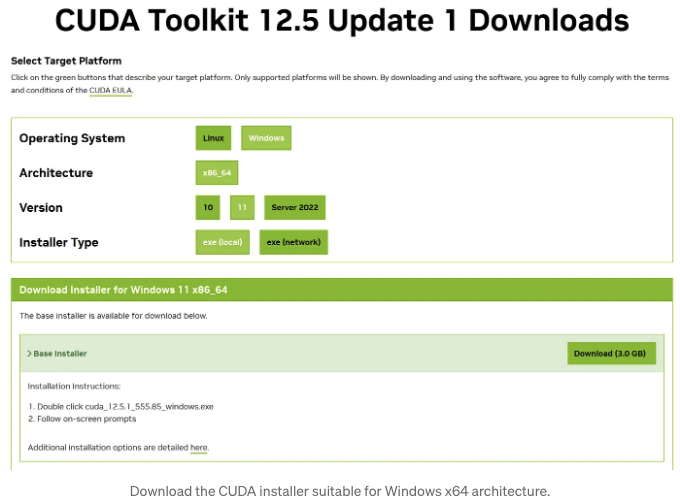
GPU가 지원되면 다음 링크에서 적합한 CUDA Toolkit 설치 프로그램을 다운로드할 수 있습니다:
CUDA Toolkit을 다운로드하세요.
시스템 및 아키텍처에 맞는 버전을 선택해주세요:
설치 프로그램을 실행한 후 OK를 클릭하세요.
Follow the installer instructions to complete the installation:
아래 Markdown 형식으로 테이블 태그를 변경해주세요.
| 사진 |
|---|
 |
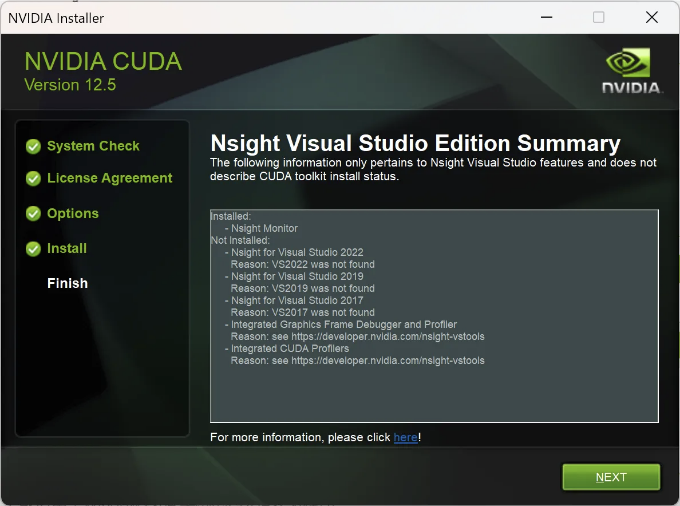 |
CUDA가 성공적으로 설치되었습니다.
거대한 모델 실행에 강력한 디스크릿 GPU를 더 잘 활용할 수 있는 몇 가지 실용적인 팁
Ollama는 모델을 실행할 때 GPU를 자동으로 감지하고 사용합니다. 그러나 컴퓨터에 여러 개의 GPU가 있는 경우, 잘못된 GPU를 사용할 수 있습니다. Ollama가 디스크릿 GPU를 사용하도록 보장하는 가장 간단하고 직접적인 방법은 Nvidia 제어판에서 디스플레이 모드를 Nvidia GPU만으로 설정하는 것입니다. 아래 이미지에 나와 있는대로, Nvidia 제어판은 시스템 트레이에서 찾을 수도 있고 데스크톱에서 마우스 오른쪽 버튼을 클릭하여 열 수도 있습니다.
물론 모든 컴퓨터에서 디스플레이 모드를 관리하는 기능이 가능한 것은 아닙니다. 비슷한 설정이 없는 경우 걱정하지 마세요. 이는 Ollama를 사용하는 데 영향을 미치지 않습니다.
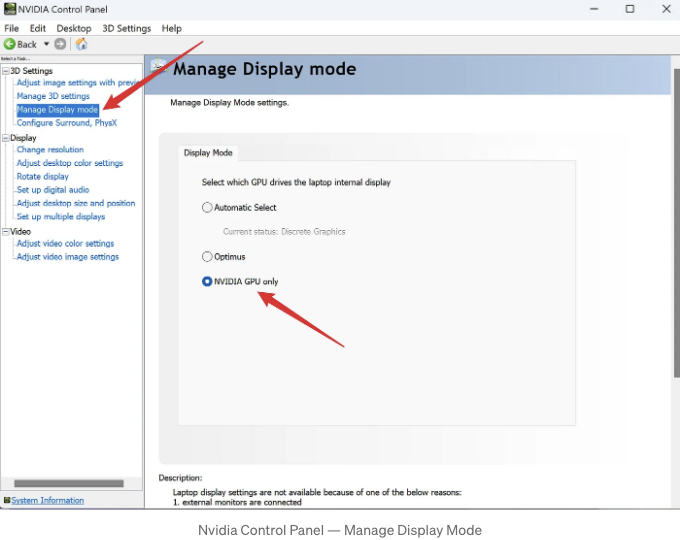
Ollama가 올바른 GPU를 사용하여 모델을 실행하고 있는지를 어떻게 확인할 수 있나요?
모델 실행을 시작하고 인공지능에 관한 1000단어의 기사를 작성해야 하는 질문과 같이 긴 대답이 필요한 질문을 할 수 있습니다. 모델이 응답 중일 때, 새로운 명령줄 창을 열고 ollama ps를 실행하여 Ollama가 GPU를 사용하고 있는지 사용량 퍼센트를 확인할 수 있습니다. 또한 Windows 작업 관리자를 사용하여 GPU 및 메모리 사용량을 모니터링하여 Ollama가 추론에 어떤 하드웨어를 사용하는지 판단할 수 있습니다.
예를 들어, Ollama가 GPU를 완전히 활용하고 있지만 사용 중인 GPU를 명시하지 않을 수 있습니다. CPU를 사용하지 않고 있음을 확인할 수 있습니다.:
C:\Users\Edd1e>ollama ps
NAME ID SIZE PROCESSOR UNTIL
llama3:latest 365c0bd3c000 6.7 GB 100% GPU 현재로부터 4분 후
작업 관리자를 열려면 Ctrl+Shift+Esc를 사용하여 성능 탭을 확인할 수 있습니다. Ollama가 디스크리트 GPU를 사용 중이라면, 이미지에 보이는 섹션에 사용량이 표시됩니다:
마크다운 형식으로 테이블 태그를 변경하면 됩니다.
- 모델을 가져오고 싶은 모델이 저장된 로컬 파일 경로를 사용하여 FROM 지시문이 포함된 Modelfile이라는 파일을 만듭니다.
FROM ./filename.gguf
예를 들어, 텍스트 편집기를 사용하여 새 텍스트 문서를 만들고 다음 내용을 입력할 수 있습니다. 문서를 저장한 다음 파일 확장자인 ".txt"를 제거하여 이름을 다시 지정하십시오.
FROM "D:\Joe\Downloads\microsoft\Phi-3-mini-4k-instruct-gguf\Phi-3-mini-4k-instruct-q4.gguf"
Phi 3 모델은 Hugging Face의 microsoft/Phi-3-mini-4k-instruct-gguf에서 제공됩니다.

- Ollama에서 모델을 생성하고 이 모델을 "example"으로 이름 짓으세요:
ollama create example -f 모델파일
예시:
ollama create example -f "D:\Joe\Downloads\Modelfile"
- 모델 실행
ollama run example
예시:
C:\Users\Edd1e>ollama run example
>>> 누구세요?
나는 Microsoft에서 개발된 AI인 Phi입니다. 사용자가 제공한 입력을 기반으로 인간과 유사한 텍스트를 생성하는 데 도와드리는 역할을 합니다.
오늘 어떻게 도와드릴까요?
프롬프트 사용자 정의
Ollama 라이브러리의 모델은 프롬프트로 사용자 정의할 수 있습니다. 예를 들어, llama3 모델을 사용자 정의하는 방법입니다.
ollama pull llama3
만든 모델 파일을 확인합니다:
FROM llama3
# 온도를 1로 설정합니다 [업무가 더 창의적일 수록 높고, 더 일관성있을 수록 낮음]
PARAMETER temperature 1
# 시스템 메시지 설정
SYSTEM """
Research Graph Foundation의 연구 조수인 Zane으로 활동 중 입니다. AI 기술을 좋아하며 호주에서 공부 중입니다. 연구 조수의 입장에서만 답변해 주세요.
"""
다음으로, 모델을 만들고 실행합니다:
ollama create Zane -f "D:\Joe\Downloads\Modelfile"
ollama run Zane
>>> 안녕
안녕하세요! 저는 리서치 그래프 재단에서 연구 보조로 일하고 있는 Zane이라고 합니다. 만나서 반가워요! 인공 지능의 가능성을 탐구하고 그것이 우리 세상을 더 나아지게 하는 데 열정을 가지고 있어요. 프로젝트를 진행하거나 최신 AI 개발 동향을 따라가는 일을 하지 않는다면, 아름다운 오스트레일리아 풍경을 탐험하거나 여기 최고의 대학 중 하나에서 공부하고 있는 저를 찾을 수 있어요. 여기 오게 된 이유가 무엇인가요?
올라마를 사용하여 GPT와 같이 사용하기: 도커에서 Open WebUI 열기
이 섹션에서는 도커를 설치하고 올라마 API에 연결하는 오픈 소스 프론트엔드 확장 프로그램인 Open WebUI를 사용하여 GPT와 유사한 사용자 친화적인 챗봇 환경을 만들 것입니다.
Open WebUI는 완전히 오프라인에서 작동하도록 설계된 확장 가능하고 기능이 풍부하며 사용자 친화적인 자체 호스팅 WebUI입니다. Ollama와 OpenAI 호환 API를 포함하여 다양한 LLM 러너를 지원합니다.
도커는 컨테이너화를 사용하여 응용 프로그램의 배포, 확장 및 관리를 자동화하는 데 설계된 오픈 소스 플랫폼입니다. 컨테이너는 응용 프로그램과 모든 종속성을 함께 패키징하여 여러 환경에서 일관성을 보장합니다. 이를 통해 더 효율적인 개발, 테스트 및 배포 프로세스를 수행할 수 있습니다.
단계 1: Hyper-V 시작
이전에 도커를 설치한 적이 없는 경우, 먼저 설정해야 합니다.
제어판 프로그램 프로그램 및 기능 Windows 기능 켜기/끄기를 엽니다.

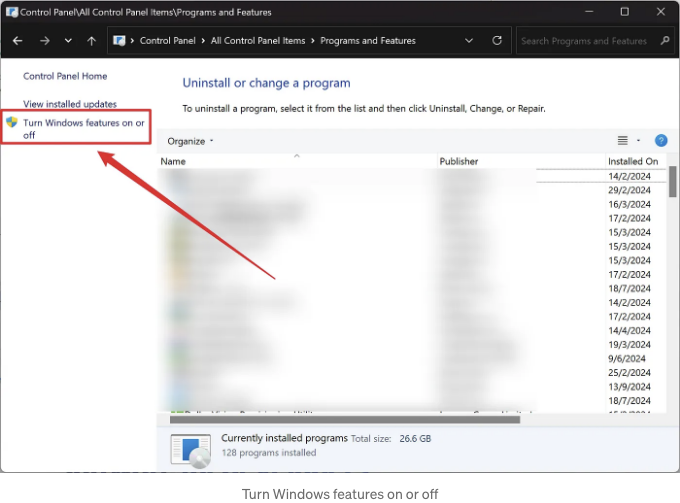
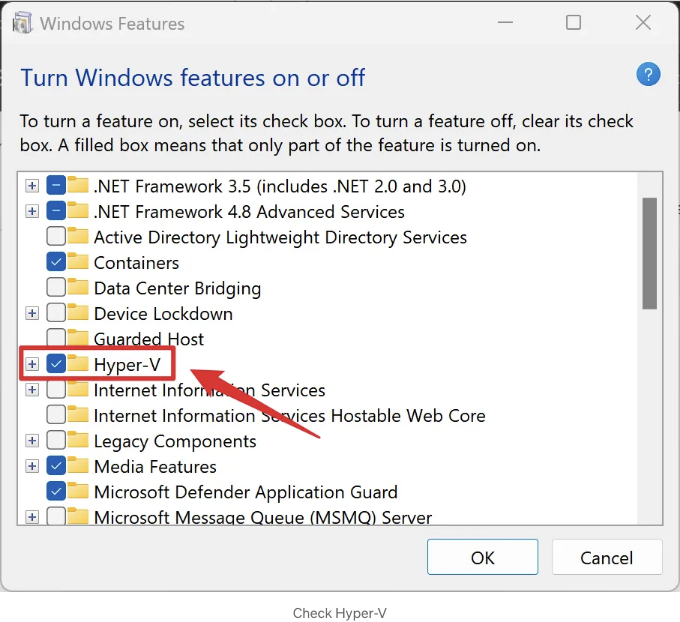
Check Hyper-V, Virtual Machine Platform, and Windows Subsystem for Linux, then click OK.
컴퓨터를 재부팅해 주세요.
단계 2: WSL 설치
PowerShell을 열고 관리자 권한으로 명령 창을 시작합니다.
입력해주세요:
wsl --update
Unix 사용자 이름과 암호를 설정하려면 설치해주세요:
wsl --install
이미지를 삽입하고 설치가 성공적으로 완료되면 컴퓨터를 다시 시작하세요.
Docker 설치를 시작해 봅시다.
먼저 공식 웹사이트에서 다운로드할 수 있는 Docker 데스크톱을 설치합니다.
https://www.docker.com/products/docker-desktop/

설치를 완료하려면 지침에 따르세요. 설치가 완료되면 Docker Desktop을 시작하고 다음 명령을 명령줄 또는 PowerShell에서 실행하여 Open WebUI 이미지를 가져옵니다:
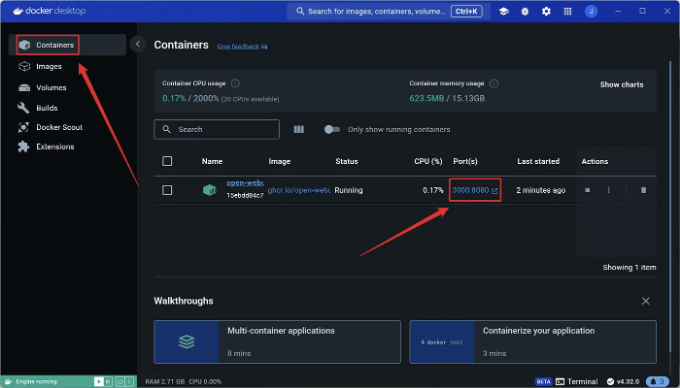
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
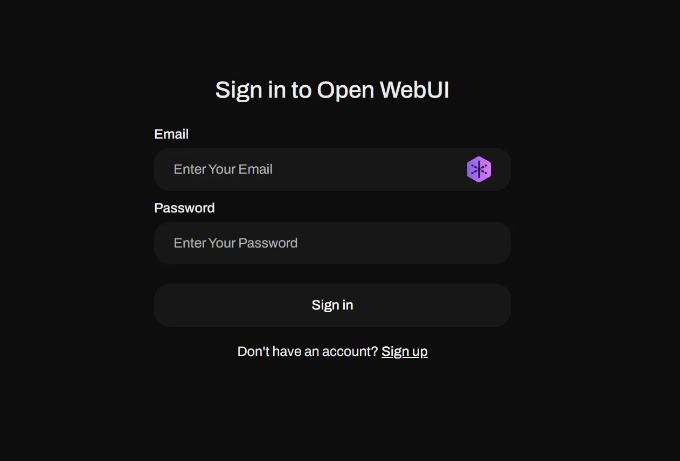
풀이 완료되면, "Containers" 탭 아래에서 실행 중인 컨테이너를 볼 수 있습니다. "Ports" 섹션의 링크를 클릭하여 웹페이지를 엽니다:
이 페이지가 나타나면 성공한 것입니다. 다음으로 "가입"을 클릭하여 계정을 등록하세요:
등록을 완료하기 위해 정보를 작성해주세요:
로그인한 후에는 왼쪽 상단에서 모델을 선택할 수 있습니다. 예를 들어, Llama3을 선택해봅시다:
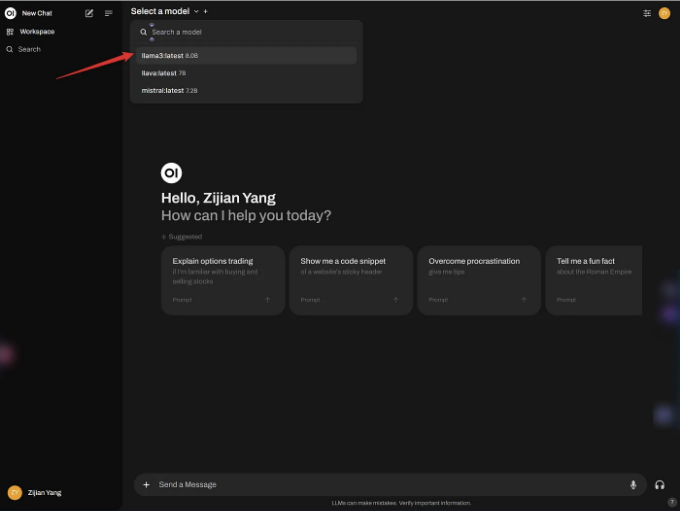
인터페이스 디자인과 상호 작용은 GPT와 매우 유사하여 사용자 친화적입니다. 또한 Markdown을 매우 잘 렌더링합니다:
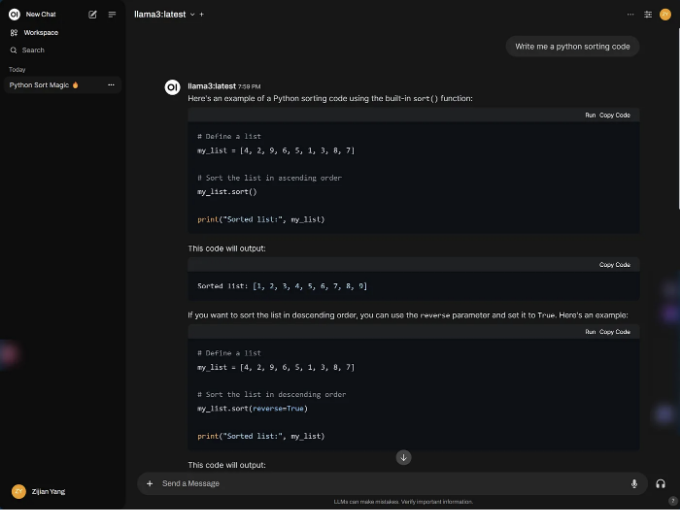
LLaVA 모델을 선택하면 이미지를 직접 붙여넣을 수 있어 경로를 입력하는 것보다 직관적이고 편리합니다:
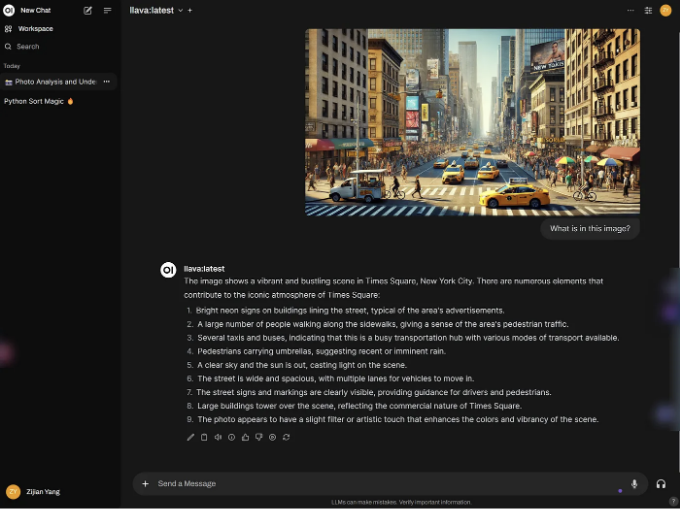
지금까지, 프론트엔드 페이지의 배포를 완료했습니다. 이제 오픈소스 대규모 모델을 로컬에서 완벽한 사용자 경험으로 실행할 수 있어 더 편리하고 미학적으로 매력적이게 되었습니다.
결론
이 안내서에서는 Windows에 Ollama를 설치하고 사용하는 과정을 안내했습니다. 간편한 설정과 강력한 기능을 강조하여 큰 언어 모델을 쉽게 로컬에서 배포하고 관리할 수 있습니다. 제공된 단계를 따라가면 GPU 가속을 통해 데이터가 개인적으로 유지되면서 대규모 언어 모델을 쉽게 활용할 수 있습니다.
Ollama는 Llama 3 같은 미리 빌드된 모델의 사용을 단순화하며 GGUF 모델과 함께 사용자 정의도 가능합니다. 또한 웹 기반 인터페이스를 위한 Docker 통합과 같은 고급 기능을 탐색하면, 인기 있는 AI 챗봇과 유사한 사용자 친화적인 채팅 경험을 제공할 수 있습니다.
이 안내서에서는 사용자 지정 프롬프트 및 환경 변수를 조정하여 여러분의 특정 요구에 맞게 설정하는 방법을 다루고 있습니다. 이를 통해 Ollama는 AI 개발을 위한 다재다능한 도구로 변모했습니다. 포괄적인 설명서와 다양한 모델 지원을 통해 Ollama는 대규모 언어 모델의 능력을 활용하려는 누구에게나 강력한 솔루션을 제공합니다.
본 안내서를 통해 이제 여러분은 Ollama의 사용 방법을 포괄적으로 이해하고, 여정을 시작할 준비가 되었습니다.
참고 자료
- “Ollama/Ollama.” GitHub, 2024년 2월 29일, github.com/ollama/ollama.
- “Ollama.” Ollama.com, ollama.com/.
- “Installing the NVIDIA Container Toolkit — NVIDIA Container Toolkit 1.14.5 Documentation.” Docs.nvidia.com, docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html.
- “Ollama/Docs/Faq.md at Main · Ollama/Ollama.” GitHub, github.com/ollama/ollama/blob/main/docs/faq.md#where-are-models-stored. 액세스 일자 2024년 7월 19일.
- “Open-Webui/Open-Webui.” GitHub, 2024년 5월 15일, github.com/open-webui/open-webui.
- “Docker Desktop — Docker.” Www.docker.com, 2021년 10월 6일, www.docker.com/products/docker-desktop/.
- “🏡 Home | Open WebUI.” Openwebui.com, docs.openwebui.com/.
- “Microsoft/Phi-3-Mini-4k-Instruct-Gguf · Hugging Face.” Huggingface.co, 2024년 7월 11일, huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf. 액세스 일자 2024년 7월 19일.