고급 SQL 마스터하는 데 필요한 문법, 사용 사례 및 전문가 팁

기술 산업에서 오랜 기간 일해온 경험 많은 데이터 전문가로서 대량의 데이터 세트를 처리해 왔습니다. SQL은 데이터 조작, 데이터 쿼리 및 분석을 위한 가장 빈번하게 사용되는 도구입니다. 기본 및 중급 SQL을 숙달하는 것은 비교적 쉽지만, 이 도구를 숙달하고 다양한 시나리오에서 능숙하게 다루기는 때로는 어려울 수 있습니다. 최고 기술 기업에서 근무하고 싶다면 익숙해져야 할 고급 SQL 기술 몇 가지가 있습니다. 오늘은 귀하가 업무에서 확실히 활용할 것으로 예상되는 가장 유용한 고급 SQL 기술을 공유하겠습니다. 더 잘 이해하기 위해 사용 사례를 만들고, 사용하는 시나리오와 사용 방법을 설명하기 위해 모의 데이터를 사용하겠습니다. 각 사용 사례에 대해 프로그래밍 코드도 제공될 것입니다.
윈도우 함수
윈도우 함수는 쿼리로부터 지정된 행 집합, 즉 "윈도우"를 통해 계산을 수행하고 현재 행과 관련된 단일 값이 반환됩니다.
윈도우 함수를 설명하기 위해 스타 백화점에서의 프로모션 판매 데이터를 사용하고자 합니다. 이 테이블에는 Sale_Person_ID(각 판매 직원의 고유 ID), Department(판매 직원 소속 부서), Sales_Amount(프로모션 중 각 직원의 판매 실적) 세 열이 포함되어 있습니다. 스타 백화점 경영진은 각 부서별 소계 판매 금액을 확인하고 싶어합니다. 여러분에게 주어진 작업은 테이블에 dept_total이라는 열을 추가하는 것입니다.
먼저, Database에 3개 열을 가진 promo_sales 테이블을 생성합니다.
CREATE TABLE promo_sales(
Sale_Person_ID VARCHAR(40) PRIMARY KEY,
Department VARCHAR(40),
Sales_Amount int
);
INSERT INTO promo_sales VALUES (001, 'Cosmetics', 500);
INSERT INTO promo_sales VALUES (002, 'Cosmetics', 700);
INSERT INTO promo_sales VALUES (003, 'Fashion', 1000);
INSERT INTO promo_sales VALUES (004, 'Jewellery', 800);
INSERT INTO promo_sales VALUES (005, 'Fashion', 850);
INSERT INTO promo_sales VALUES (006, 'Kid', 500);
INSERT INTO promo_sales VALUES (007, 'Cosmetics', 900);
INSERT INTO promo_sales VALUES (008, 'Fashion', 600);
INSERT INTO promo_sales VALUES (009, 'Fashion', 1200);
INSERT INTO promo_sales VALUES (010, 'Jewellery', 900);
INSERT INTO promo_sales VALUES (011, 'Kid', 700);
INSERT INTO promo_sales VALUES (012, 'Fashion', 1500);
INSERT INTO promo_sales VALUES (013, 'Cosmetics', 850);
INSERT INTO promo_sales VALUES (014, 'Kid', 750);
INSERT INTO promo_sales VALUES (015, 'Jewellery', 950);
다음으로, 각 부서의 소계 판매액을 계산하고 테이블 promo_sales에 dept_total 열을 추가해야 합니다. 창 함수를 사용하지 않고는 "GROUP BY" 절을 사용하여 각 부서의 판매액을 얻는 "department_total"이라는 다른 테이블을 만듭니다. 그런 다음 테이블 promo_sales와 department_total을 조인합니다. 창 함수를 사용하면 이러한 계산을 단일 SQL 쿼리 내에서 수행할 수 있는 강력한 방법을 제공하여 데이터 처리 작업을 간소화하고 최적화할 수 있습니다.
이 작업을 수행하기 위해 SUM() 함수를 사용할 수 있습니다.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
SUM(Sales_Amount) OVER (PARTITION BY Department) AS dept_total
FROM
promo_sales;
그런 다음 테이블 promo_sales에 예상대로 dept_total이라는 하나의 추가 열이 있습니다.
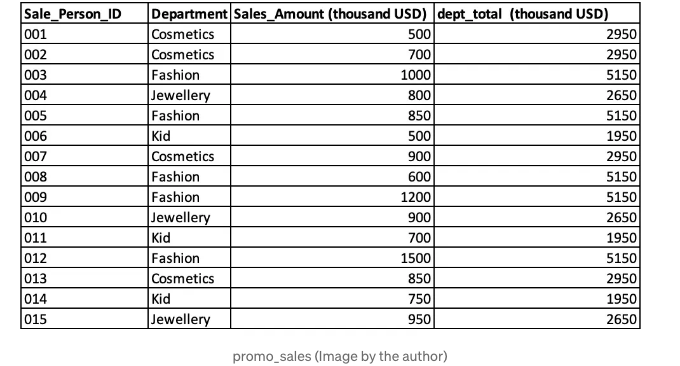
이 예제는 창 함수가 결과 집합의 행 수를 줄이지 않는다는 것을 보여줍니다. GROUP BY와 함께 사용되는 집계 함수와 달리 창 함수는 누적 합계, 평균 및 카운트와 같은 계산을 수행할 수 있으며 순위 매기기와 같은 작업에도 사용할 수 있습니다. 이제 다음 예제로 넘어가 보겠습니다.
Star Department Store의 경영진은 각 부서 내 프로모션 기간 동안의 성과에 따라 영업 직원들을 순위 매기고 싶어 합니다. 이번에는 영업 직원들을 순위 매기기 위해 RANK() 함수를 사용할 수 있습니다.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
RANK() OVER (PARTITION BY Department ORDER BY Sales_Amount DESC) AS Rank_in_Dept
FROM
promo_sales;
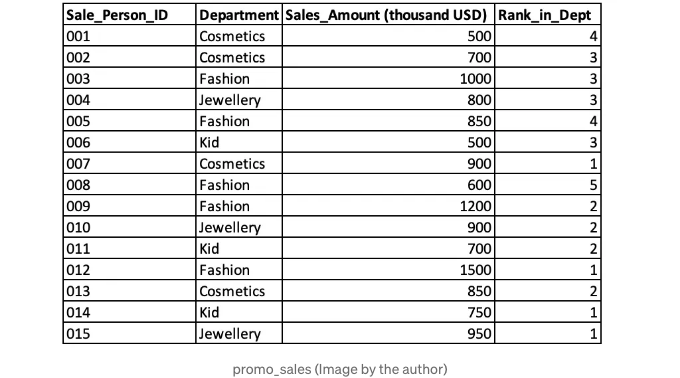
윈도우 함수는 데이터 분석에서 널리 사용됩니다. 윈도우 함수의 일반적인 유형에는 순위 함수, 집계 함수, 오프셋 함수 및 분포 함수가 있습니다.
- 순위 함수: 순위 함수는 결과 집합의 파티션 내 각 행에 순위 또는 행 번호를 할당합니다.
-
ROW_NUMBER(): 각 행에 고유한 연속 정수를 할당합니다.
-
RANK(): 동점이 있는 경우 간격을 두고 순위를 할당합니다.
-
DENSE_RANK(): 동점이 있는 경우 간격 없이 순위를 할당합니다.
-
NTILE(n): 행을 대략적으로 동일한 n 그룹으로 나눕니다.
- 집계 함수: 집계 함수는 현재 행과 관련된 행 집합 전체에서 계산을 수행하거나 통계를 수행하는 데 사용됩니다.
-
SUM (): 파티션 내 전체 값 계산
-
AVG (): 파티션 내 평균 값 계산
-
COUNT (): 파티션 내 원소 수 얻기
-
MAX(): 파티션 내에서 가장 큰 값 가져오기
-
MIN(): 파티션 내에서 가장 작은 값 가져오기
- Offset 함수: Offset 함수를 사용하면 현재 행과 관련된 다른 행의 데이터에 액세스할 수 있습니다. 행 간 값 비교가 필요하거나 시계열 분석 또는 트렌드 감지를 실행해야 할 때 사용됩니다.
- LAG(): 이전 행에서 데이터에 액세스
-
LEAD(): 다음 행의 데이터에 액세스합니다.
-
FIRST_VALUE(): 정렬된 세트에서 첫 번째 값을 가져옵니다.
-
LAST_VALUE(): 정렬된 세트에서 마지막 값을 가져옵니다.
- 분포 함수: 분포 함수는 값이 값 그룹 내의 상대적 위치를 계산하고 값의 분포를 이해하는 데 도움이 됩니다.
-
PERCENT_RANK(): 한 행의 백분위 순위를 계산합니다.
-
CUME_DIST(): 값의 누적 분포를 계산합니다.
-
PERCENTILE_CONT(): 연속 백분위 값을 계산합니다.
-
PERCENTILE_DISC(): 이산적인 백분위 값을 계산합니다.
서브쿼리
서브쿼리는 다른 SQL 쿼리 내에 있는 쿼리로, 중첩 쿼리 또는 내부 쿼리로도 알려져 있습니다. 새로운 열이나 새로운 테이블을 생성하거나 메인 쿼리에서 검색할 데이터를 더 제한하는 조건을 생성하는 데 사용할 수 있습니다.
데모를 위해 스타 백화점의 데이터 테이블 promo_sales를 계속 사용해 보겠습니다.
- 새로운 열 생성을 위한 서브쿼리
이번에는 각 세일즈 직원의 판매 금액과 부서 평균 간의 차이를 보여주는 새로운 열을 추가하고 싶습니다.
SELECT
Sale_Person_ID,
Department,
Sales_Amount,
Sales_Amount - (SELECT AVG(Sales_Amount) OVER (PARTITION BY Department) FROM promo_sales) AS sales_diff
FROM
promo_sales;
- 새 테이블을 생성하기 위한 서브쿼리
마케팅 비용 테이블 mkt_cost에는이 프로모션 동안 모든 부서의 광고 비용이 포함되어 있습니다. 각 부서의 광고 비용 효율성이 가장 높은 부서를 결정하려면 각 부서의 광고 지출 대비 매출액을 계산해야 합니다. 우리는 서브쿼리를 사용하여 이러한 부서들을 위해 총 판매 금액과 마케팅 비용을 포함하는 새로운 테이블을 만들고, 이 새로운 테이블의 데이터를 분석할 수 있습니다.
SELECT
Department,
dept_ttl,
Mkt_Cost,
dept_ttl/Mkt_Cost AS ROAS
FROM
(SELECT
s.Department,
SUM(s.Sales_Amount) AS dept_ttl,
c.Mkt_Cost
FROM
promo_sales s
LEFT JOIN
mkt_cost c
ON s.Department=c.Department
GROUP BY s.Department
)
- 제한 조건을 만드는 서브쿼리
서브쿼리를 사용하여 모든 판매 대행자의 평균 판매액을 초과한 판매 대행자를 선택할 수도 있습니다.
SELECT
Sale_Person_ID,
Department,
Sales_Amount
FROM
promo_sales
WHERE
Sales_Amount > (SELECT AVG(salary) FROM promo_sales);
위에 나열된 3가지 유형의 서브쿼리 외에도 자주 사용되는 서브쿼리 유형이 있습니다. 이것은 외부 쿼리의 값에 의존하는 '상관 서브쿼리'입니다. 이 서브쿼리는 외부 쿼리의 각 행마다 한 번 실행됩니다.
상관 서브쿼리는 프로모션 기간 동안 부서 평균 이상의 매출 실적을 달성한 판매 담당자를 찾는 데 사용할 수 있습니다.
SELECT
ps_1.Sale_Person_ID,
ps_1.Department,
ps_1.Sales_Amount
FROM
promo_sales ps_1
WHERE
ps_1.Sales_Amount > (
SELECT AVG(ps_2.Sales_Amount)
FROM promo_sales ps_2
WHERE ps_2.Department = ps_1.Department
);
서브쿼리를 사용하면 데이터에 대해 복잡한 질문에 답할 수 있는 복잡한 쿼리를 작성할 수 있어요. 그러나 대규모 데이터셋의 경우 과도한 사용은 성능 문제로 이어질 수 있으니 신중히 사용하는 것이 중요해요.
공통 테이블 표현식
공통 테이블 표현식(CTE)은 하나의 SQL 문 범위 내에서 존재하는 이름이 붙은 임시 결과 집합이에요. CTE는 WITH 절을 사용하여 정의되며 후속 SELECT, INSERT, UPDATE, DELETE 또는 MERGE 문에서 한 번 이상 참조될 수 있어요.
SQL에서 주로 두 가지 유형의 CTE가 있어요.
- Non-recursive CTE: 비재귀 CTE는 복잡한 쿼리를 간단한 부분으로 분해하여 단순화하는 데 사용됩니다. 자기 자신을 참조하지 않기 때문에 CTE의 가장 간단한 유형입니다.
- Recursive CTE: 재귀 CTE는 정의 내에서 자기 자신을 참조하여 계층적 또는 트리 구조 데이터를 처리할 수 있습니다.
이제 비재귀 CTE를 사용하여 데이터 테이블 promo_sales를 처리해 보겠습니다. 과제는 각 부서별 판매액의 평균을 계산하고 프로모션 중 평균 매출과 비교하는 것입니다.
WITH dept_avg AS (
SELECT
Department,
AVG(Sales_Amount) AS dept_avg
FROM
promo_sales
GROUP BY
Department
),
store_avg AS (
SELECT AVG(Sales_Amount) AS store_avg
FROM promo_sales
)
SELECT
d.Department,
d.dept_avg,
s.store_avg,
d.dept_avg - s.store_avg AS diff
FROM
dept_avg d
CROSS JOIN
store_avg s;
재귀 CTE는 계층적 데이터를 처리할 수 있기 때문에 1에서 10까지 숫자 시퀀스를 생성하려고 합니다.
WITH RECURSIVE sequence_by_10(n) AS (
SELECT 1
UNION ALL
SELECT n + 1
FROM sequence_by_10
WHERE n < 10
)
SELECT n FROM sequence_by_10;
CTE(공통 테이블 표현식)는 복잡한 쿼리를 단순화하여 가독성과 유지보수성을 향상시킴으로써 강력한 기능을 제공합니다. 메인 쿼리에서 동일한 서브쿼리를 여러 번 참조해야 할 때나 재귀 구조와 함께 작업할 때 특히 유용합니다.
결론
세 가지 고급 SQL 기술은 데이터 처리 및 분석 기능을 크게 향상시킬 수 있습니다. 윈도우 함수를 사용하면 개별 레코드의 맥락을 유지하면서 행 집합 전체에 대한 복잡한 계산을 수행할 수 있습니다. 서브쿼리를 사용하면 데이터에 대해 정교한 질문에 대답하기 위한 복잡한 쿼리를 작성할 수 있습니다. CTE는 SQL 쿼리를 구조화하고 단순화하는 강력한 방법을 제공하여 가독성과 유지보수성을 높일 수 있습니다. 이러한 고급 기술을 SQL 도구상자에 통합함으로써 데이터 전문가로서의 역할에서 복잡한 데이터 도전에 대처하고 가치 있는 통찰을 제공하거나 이야기하는 대시보드를 생성하는 데 SQL 기술을 업그레이드할 수 있어야 합니다.