
새로운 브런치 카페를 오픈하려고 하거나 기존 카페를 활성화하려는 중이신가요? 혹은 새로운 사업으로 공유 오피스 스페이스를 고려 중이신가요? 어떤 목표를 가지고 있든, 경쟁 업체의 전략을 이해하는 것이 중요합니다. Google 지도 리뷰는 시장 조사에 매우 유용한 정보를 제공해줍니다. 비지니스 결정에 도움을 줄 수 있는 소중한 통찰을 제공해줍니다.
Google 지도에서 리뷰를 수작업으로 수집하는 것은 작은 특정 시장이나 리뷰 수가 제한적인 경우에만 가능한 지침작업입니다. 그 대안으로 웹 스크레이핑을 통해 리뷰를 추출할 수 있는 유료 API를 활용하거나 무료로 자체 스크레이퍼 스크립트를 만들 수 있습니다. 이 글에서는 후자의 옵션을 탐구하고 무료로 자체 스크레이퍼 스크립트를 작성하는 방법을 안내해 드리겠습니다.
웹 스크레이핑을 통해 Google 지도 리뷰를 추출하기 위해 프로그래밍 언어로 Python을 사용하고 Playwright를 사용하여 헤드리스 브라우징을 할 것입니다. 이를 통해 자바스크립트가 많이 사용된 콘텐츠의 복잡성을 처리할 수 있어 클릭, 폼 작성, 요소 찾기 및 기타 자동화 작업을 수행할 수 있습니다.
스크립트를 시작하기 전에, Playwright의 기능을 탐험해 보는 시간을 가져봅시다. 그 다음에는 Google 지도 리뷰를 추출하는 장점과 기업 및 개인에게 가치 있는 자원이 되는 이유에 대해 이야기할 거예요. 마지막으로는 카페, 박물관, 호텔 등 여러 장소를 입력하고 찾고자 하는 소중한 리뷰를 검색할 수 있는 실용적인 스크립트로 모두를 연결할 거예요.
웹 스크래핑 Google 지도 리뷰: 도구들
웹 스크래핑을 위해 여러 프로그래밍 언어를 사용할 수 있으며, 그중 가장 일반적인 것은 JavaScript, Python, R, Java, Ruby입니다. 그러나 Python은 광범위한 웹 스크래핑 라이브러리를 가지고 있어 가장 유연하고 사용하기 쉬운 언어로 두드러집니다. 이 Python 라이브러리들 중에는 HTML 파서, 헤드리스 브라우저, 요청 라이브러리 등이 있으며, 각각 웹 스크래핑과 자동화 작업에서 고유한 목적을 제공합니다.
- HTML 파서: Beautiful Soup 및 Scrapy와 같은 라이브러리들은 HTML과 XML 문서에서 데이터를 추출하고 조작하는 데 사용됩니다. 개발자들이 태그나 속성을 기반으로 요소를 선택하고 데이터를 더 유용한 형식으로 변환할 수 있게 합니다.
- 헤드리스 브라우저: Selenium 및 Playwright와 같은 도구들은 헤드리스 브라우저로 실제 웹 브라우저를 시뮬레이션합니다. 이러한 라이브러리들은 동적 웹사이트와 상호작용이 필요한 작업에 강력하며, 버튼 클릭, 양식 작성, JavaScript 실행과 같은 작업에 유용합니다. 헤드리스 브라우저는 간단한 HTTP 요청만으로는 전체 내용을 캡처할 수 없는 상황에서 자주 사용됩니다.
- 요청 라이브러리: requests 및 httpx와 같은 라이브러리들은 HTTP 요청을 처리할 수 있도록 설계되어 있어, 웹 서버에 GET, POST 및 기타 유형의 요청을 간편하게 보낼 수 있습니다. 이러한 라이브러리들은 웹 API와 상호작용하거나 웹 페이지를 다운로드하거나 양식에 데이터를 제출하는 데 기본적입니다.
저희의 웹 스크래핑 스크립트에서는 Google Maps에서 데이터를 스크레이핑할 때 Playwright 헤드리스 브라우저만 사용하게 됩니다. 나중에 이 글에서 HTML 파서가 필요하지 않은 이유를 이해하게 될 것입니다.
Playwright
헤드리스 브라우저 중에서 Selenium이 Python에서 가장 인기 있는 도구로, 다양한 언어 지원과 방대한 문서를 제공합니다. 그러나 저는 Selenium이 크롬 드라이버를 다운로드해야 한다는 점이 불편하다고 생각했습니다. 반면에 Playwright는 이 단계를 건너뛸 수 있는 최신 헤드리스 브라우저입니다. 더불어, Playwright는 최신 웹사이트에 대해 더 나은 지원을 제공하고 쉽게 따라갈 수 있으며 다양한 프로그래밍 언어로 제공되는 풍부한 문서를 통해 처리 속도가 빠르다고 알려져 있습니다.
웹 스크래핑 Google Maps 리뷰의 응용
웹 스크래핑을 활용해 구글 맵 리뷰를 분석할 수 있는 애플리케이션은 다양합니다. 아래에 몇 가지 예시를 소개해 드릴게요:
- 감성 분석: 구글 맵에서 리뷰와 평점을 추출하여 비즈니스, 위치 또는 서비스에 대한 고객 의견을 분석합니다. 이를 통해 강점과 약점을 파악하는 데 도움이 될 수 있어요.
- 경쟁사 분석: 경쟁사의 리뷰를 추출하여 평판, 고객 만족도 및 시장 동향을 비교합니다.
- 시장 조사: 구글 맵 리뷰를 스크래핑하여 특정 제품, 서비스 또는 산업에 대한 고객 선호도, 행동 및 의견 데이터를 수집합니다.
- 평판 관리: 리뷰와 평점을 추적하여 비즈니스의 온라인 평판을 모니터링하고 관리합니다.
- SEO 향상: 구글 맵 리뷰, 평점 및 키워드를 분석하여 검색 엔진 최적화 전략을 구현합니다.
- 고객 피드백 분석: 제품, 서비스 또는 고객 경험을 개선하기 위해 고객 피드백의 패턴과 트렌드를 식별합니다.
- 비즈니스 인텔리전스: 리뷰 데이터를 활용하여 신규 비즈니스 기회나 개선할 부분을 식별하는 데 사용합니다.
위에서 소개한 응용 프로그램을 바탕으로 몇 가지 실제 사용 사례를 살펴보겠습니다:
- 호텔은 구글 맵 리뷰를 스크래핑하여 온라인 평판을 모니터링하고 개선할 부분을 확인하며 경쟁사와의 성과를 비교할 수 있습니다.
- 여행사는 구글 맵 리뷰를 스크래핑하여 여행지, 숙소 및 활동에 관한 피드백을 분석합니다. 이를 통해 맞춤형 추천을 제공하고 여행 상품을 최적화하며 고객 만족도를 향상시킬 수 있습니다.
- 소매점은 구글 맵 리뷰를 스크래핑하여 상점, 제품 및 서비스에 대한 고객 피드백을 분석합니다. 이를 통해 개선할 부분을 확인하고 재고를 최적화하며 고객 경험을 향상시킬 수 있습니다.
위에서 몇 가지 사용 사례를 나열했지만, 더 많이 있습니다. 구글 맵 리뷰는 경쟁 업체 앞서가거나 현명한 결정을 내리려는 기업과 개인들에게 필수적인 데이터 소스입니다.
플레이 라이트를 사용하여 구글 맵 리뷰를 웹 스크레이핑하는 전체 스크립트
웹 스크레이핑 스크립트에 도약하기 전에, 구글 맵 리뷰를 스크레이핑하는 여러 가지 방법이 있다는 점을 언급하는 것이 중요합니다. 저희가 공유할 방법은 하나의 예시에 불과하며, 효율적이거나 특정 요구 사항에 맞춘 것은 아닐 수 있지만 무료이며 유연한 시작점으로 활용될 수 있습니다. 유료 API에 의존하지 않고 필요에 맞게 수정하고 조정하여 사용하실 수 있습니다.
먼저, pip 명령으로 Playwright를 설치해야 합니다:
pip install playwright
이제 Selenium과 달리 Chromedriver를 다운로드해야 하는 번거로움 없이 Playwright를 사용하여 다음 명령어로 간단히 브라우저를 설치할 수 있습니다:
playwright install
웹 스크래핑 부분에 필요한 유일한 패키지이지만, 추출된 데이터를 데이터프레임으로 변환하는 섹션을 추가했기 때문에 Pandas를 설치해야 합니다:
pip install pandas
의존성을 가져와 Playwright를 인스턴스화하여 시작해 봅시다:
import time
import os
import asyncio
import json
import pandas as pd
from playwright.async_api import async_playwright
# 구글의 주요 URL
url = (
"https://www.google.com/maps/@38.7156642,-9.1243907,16z?entry=ttu")
async with async_playwright() as pw:
# Chromium 브라우저의 인스턴스를 생성하고 실행합니다
browser = await pw.chromium.launch(headless=False)
# 브라우저 인스턴스 내에서 새로운 브라우저 페이지(탭)를 생성합니다
page = await browser.new_page()
# Playwright 페이지 요소를 사용하여 URL로 이동합니다
await page.goto(url)
# 쿠키를 거부합니다
await page.locator("text='Reject all'").first.click()
# 찾고자 하는 내용을 입력합니다
await page.fill("#searchboxinput", "Homie's - a local joint")
이 첫 번째 코드 조각에서는 Chromium 브라우저의 인스턴스를 생성합니다(다른 브라우저도 사용할 수 있습니다. Firefox나 WebKit 같은). 그런 다음 자동화 작업을 수행하는 브라우저 페이지를 생성합니다. 우리는 먼저 Google 지도의 대상 URL로 이동합니다(기본 Google 지도 URL을 복사하여 사용하십시오. 여러분의 위치에 따라 제가 사용하는 URL과 다를 수 있습니다).
두 번째로, 우리는 "모두 거절" 텍스트를 찾아 클릭합니다. 만약 비영어권 국가에 위치해 있다면, 스페인어로 "모두 거절" 같은 다른 용어를 발견할 수도 있습니다. 그런 경우에는 로케이터 입력을 국가 언어에 맞게 변경해주세요. 또는 CSS 클래스를 대상으로 지정할 수도 있지만, 추가 조치가 필요할 수 있습니다.
세 번째로, 쿠키 탭을 닫은 후, 페이지.fill() 함수로 검색 창에 입력할 수 있습니다. 저는 리스본에서 참 좋아하는 바/카페인 Homie's 리뷰를 검색하기로 결정했습니다.
크롬 인스턴스를 실행할 때 headless를 False로 설정하여 실시간으로 스크레이퍼가 작동하는 것을 보고 싶다면, Playwright와 함께 수행하는 모든 작업을 보여주는 그래픽 사용자 인터페이스(GUI)를 열 수 있습니다.
아래는 우리의 코드를 계속하겠습니다.
# 이전 코드 스니펫의 동일한 들여쓰기에서 진행합니다.
time.sleep(2)
# 옵션 목록에서 첫 번째 요소 선택
await page.keyboard.press('ArrowDown')
await page.keyboard.press('Enter')
# 리뷰 탭으로 이동
await page.locator("text='Reviews'").first.click()
# 최신 리뷰로 정렬
await page.locator("text='Sort'").first.click()
time.sleep(1)
await page.keyboard.press('ArrowDown')
time.sleep(1)
await page.keyboard.press('Enter')
카페 이름을 입력한 후, 모든 가능한 옵션을 나열하는 데 2초를 기다립니다. 카페 이름을 올바르게 지정했다면, 첫 번째 목록의 대상이 됩니다. 따라서 page.keyboard.press('ArrowDown')를 사용하여 첫 번째 옵션으로 이동한 다음 Enter를 누르는 함수를 사용합니다.
다시 한 번, page.locator() 함수를 사용하여 리뷰 탭을 타겟팅하고 클릭합니다(로케일 언어로 번역하는 것을 잊지 마세요). 이 경우, 다른 섹션에도 Reviews라는 단어가 있기 때문에 .first 메소드를 사용합니다.
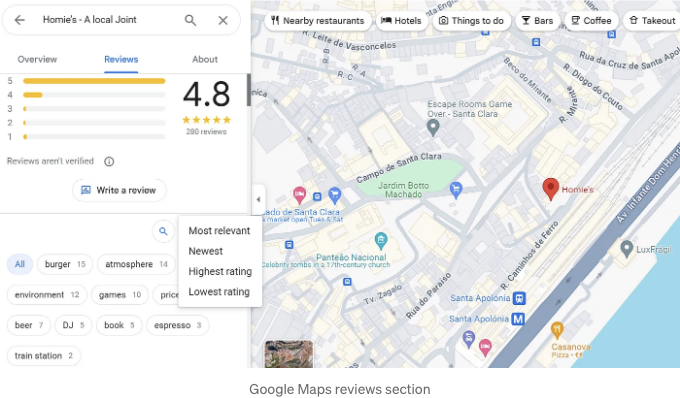
우리가 스크레이핑하려는 페이지에 드디어 도착했어요. 할 일이 한 가지 더 있습니다(선택 사항임). 위 스크립트에서 리뷰를 날짜별로 정렬했어요. Sort를 찾아 클릭하고, 키보드 기능으로 가장 최근 것을 의미하는 두 번째 옵션을 선택했습니다.
Google Maps는 무한 스크롤 웹사이트여서 데이터가 한꺼번에 렌더링되지 않아요. 새로운 데이터를 렌더링하려면 스크롤해야 하므로, 저는 데이터를 웹 스크레이핑하기 위한 두 가지 주요 방법을 찾았어요. 첫 번째 방법은 리뷰를 포함하는 HTML 클래스를 스크롤하고 파싱하는 방식이에요. 이 방법은 작동하지만 느리고 어떤 내용을 건너뛰기도 하고, 아마도 Beautiful Soup 같은 HTML 파서가 필요할 것이에요. 두 번째 방법은 더 복잡할 수 있지만, 더 빠르고 HTML 파서가 필요하지 않아요.
무한 스크롤 웹사이트에서 웹 스크레이핑하는 방법에 대해 더 알고 싶다면 아래 글을 확인해보세요:
이 기사에서는 빠르고 다른 무한 스크롤을 사용하는 웹 사이트에 대한 횡단을 고려한 두 번째 방법만 살펴볼 예정입니다. 함께 살펴봅시다:
# 이전 코드 스니펫의 들여쓰기와 동일하게 계속
for i in range(20):
await page.mouse.wheel(0, 35000)
# 응답 받기
page.on(
"response",
lambda response: asyncio.create_task(
check_json(response, path)))
print('스크롤 중')
time.sleep(1)
위의 코드 스니펫은 Google Maps 리뷰 페이지를 스크롤하고 각 반복에서 page.on() 함수를 사용하여 응답을 트리거하는 주로 루프입니다. 이 함수는 "response" 문자열을 입력으로 취하고 람다 함수 check_json()를 취하는데, 이를 자세히 분석할 것입니다.
Google Maps 리뷰 페이지를 아래와 같이 스크롤하면 Inspect를 클릭한 다음 Network를 클릭하면 아래 이미지와 같은 내용을 볼 수 있습니다.
마크다운 형식으로 표 태그를 변경하세요.
async def check_json(response, output_path):
"""이 함수는 네트워크로부터 응답을 받았을 때 호출되며 'listugcposts'를 포함하는 응답을 처리합니다. 텍스트를 JSON으로 변환하고 데이터를 얻습니다."""
if "listugcposts" in response.url:
content = await response.text()
content = content.split(")]}'\n")[1]
# JSON으로 문자열을 파싱
data_raw = json.loads(content)
data_raw = data_raw[2]
def safe_extract(data, *path, default=None):
try:
for key in path:
data = data[key]
return data
except (IndexError, KeyError, TypeError):
return default
for i, element in enumerate(data_raw):
timestamp = data_raw[i][0][1][6]
if 'year' not in timestamp and 'years' not in timestamp:
data = {
'review': safe_extract(
data_raw, i, 0, 2, 15, 0, 0),
'rating': safe_extract(
data_raw, i, 0, 2, 0, 0),
'source': safe_extract(
data_raw, i, 0, 1, 13, 0),
'timestamp': safe_extract(
data_raw, i, 0, 1, 6),
'language': safe_extract(
data_raw, i, 0, 2, 14, 0),
}
# 중복을 피하기 위해 기존 데이터를 세트로 불러옵니다.
existing_data = set()
if os.path.exists(output_path):
with open(output_path, 'r', encoding='utf-8') as file:
for line in file:
existing_data.add(line.strip())
new_data_json = json.dumps(
data, ensure_ascii=False)
if new_data_json not in existing_data:
# 새 데이터를 JSON 파일에 작성합니다.
with open(output_path, 'a', encoding='utf-8') as file:
file.write(new_data_json + '\n')
위의 함수에서는 먼저 'listugcposts'라는 용어를 포함하는 URL을 찾고, 이 경우 URL이 JSON이 아닌 텍스트 파일을 포함하고 있기 때문에 내용을 텍스트 형식으로 얻습니다. 따라서 .split() Python의 내장 함수를 사용하여 JSON으로 변환할 수 있는 용어를 얻습니다.
JSON 파일이 준비되면 데이터를 반복하며 리뷰, 평점, 소스, 타임스탬프 및 언어를 safe_extract()로 안전하게 추출합니다. safe_extract() 함수는 인덱스가 있는 요소를 찾아서 찾지 못할 경우 None을 반환합니다.
JSON 파일은 탐색하기가 상당히 어려울 수 있으므로 원하는 추출할 요소의 정확한 위치를 알기 위해 JSON Editor Online과 같은 JSON 에디터를 사용하는 것을 권장합니다.
위의 이미지에서, 왼쪽에는 원시 JSON을 복사하고 오른쪽에는 구조화된 모습으로 얻었습니다. 구조화된 파일을 탐색하여 data[i][0][2][15][0][0] 위치에 리뷰가 있는 것을 확인할 수 있어요.
위의 이미지에서, 우리는 첫 번째 위치의 리뷰를 확인할 수 있어요. data[0][0][2][15][0][0]입니다. 알아요, 인덱싱이 상당히 길긴 하지만, 가장 중요한 요소들인 리뷰, 평점, 출처, 타임스탬프, 그리고 언어를 이미 찾아뒀어서 걱정할 필요 없어요.
매 반복마다 데이터는 각 라인이 하나의 리뷰를 나타내는 JSON 파일에 저장됩니다.
여기서 코드를 완료할 수 있습니다. JSON 형식으로 스크랩된 데이터가 저장되지만 CSV로 원하신다면 다음 단계를 추가할 수 있습니다:
def read_json_as_dataframe(file_path):
"""이 함수는 리뷰가 포함된 json 파일을 읽어옵니다."""
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# 각 JSON 객체를 구문 분석하고 목록에 추가합니다.
data.append(json.loads(line))
# JSON 객체의 목록을 DataFrame으로 변환
df = pd.DataFrame(data)
return df
# csv 파일로 저장
df = read_json_as_dataframe(path)
df.to_csv('data/reviews.csv', index=False)
이것은 CSV 형식의 출력 미리보기입니다:
리뷰,평점,출처,타임스탬프,언어
"오늘의 수프, 크리미한 비건 콩 수프를 맛있게 먹었어요. 가격이 매우 리즈너블하여 로열한 양도 제공했어요. 아이스 카이도 했는데 조금 더 맛이 강해도 좋겠지만 괜찮았어요. 식물, 소파, 쿠션, 즐거운 배경 음악과 테라스가 있는 아늑한 분위기. 친절한 서비스!",5,Google,1주 전,en
,5,Google,1주 전,
정말 놀라운 음식! 때때로 변경되는 메뉴가 있지만 리스본에서 가장 좋아하는 음식 중 하나였어요.,5,Google,3주 전,en
,5,Google,1개월 전,
훌륭한 샌드위치를 저렴한 가격에 제공해요! 기차역 근처에서 아주 좋은 아침 식사 장소예요.,5,Google,1개월 전,en
로스트 미트 샌드위치는 기다릴 가치가 있어요. 11/10,5,Google,1개월 전,en
"커피를 마시는 것 같아서 완벽한 분위기. 에스프레소는 놀라운 맛이고, 카푸치노도요!",5,Google,1개월 전,en
좋은 시간을 보낼 수 있는 흥미로운 장소예요. 특별한 커피와 여러 종류의 음료, 음식, 게임을 제공해요. 에스프레소 마티니를 시식해봤어요. 정말 좋았어요.,5,Google,1개월 전,es
,4,Google,1개월 전,
"좋은 '이-파' 맥주(또는 IPA)를 제공하는 멋진 현지인 장소예요.",5,Google,1개월 전,en
"슈퍼입니다. 매우 친절하고 현대적이며 매우 청결해요. 훌륭한 햄버거도 맛있어요! 또한 새남(스펠링이 정확하지 않다면 죄송해요)은 훌륭한 팀원이에요. 그는 훌륭한 음식과 음료를 더 맛있게 만들어요.",5,Google,1개월 전,en
,5,Google,2개월 전,en
,4,Google,2개월 전,
,5,Google,2개월 전,
"놀라운, 아름답고 매우 쾌적한 공간이에요. 모두 매우 친절하고 음식도 환상적이에요. :)",5,Google,2개월 전,pt
,5,Google,3개월 전,
"정직한 스태프, 지갑을 놓고 왔는데 우리가 돌아왔을 때 우리를 위해 가지고 있었어요! 너무 감사해요. 여행 중 큰 걱정을 덜어주셨어요. 정말 너무 감사하고 기쁘네요!",5,Google,3개월 전,en
"음식과 음료가 잘 서빙되고 맛있어요 - 스탭들에게 축하드려요! 넓고 깨끗한 화장실도 있어요. 👏👏👏 다만 두 가지 아쉬운 점은 소리가 다소 크게 나서 대화할 때 목소리를 높여야 하는 점과, 식당이 꽉 차 있지 않았는데도 서비스가 늦어진 점이었어요. 심지어 2개의 샐러드가 후에 뒤따라 나온 점이었어요. 햄버거 두 개와 피카파우보 한 개보다 뒤에 서빙된 캐서롤요. 식당에 많은 성공을 빌어요.",5,Google,3개월 전,pt
"여기서 빠른 테이크아웃만 받았지만, 서비스가 훌륭해서 분명히 다시 갈 거예요.",5,Google,4개월 전,en
전체 코드
""" 이 스크립트는 Google Maps 리뷰를 스크랩합니다 """
import time
import os
import asyncio
import json
import pandas as pd
from playwright.async_api import async_playwright
def read_json_as_dataframe(file_path):
""" 이 함수는 리뷰가 있는 json 파일을 읽습니다 """
data = []
with open(file_path, 'r', encoding='utf-8') as file:
for line in file:
# JSON 객체를 구문 분석하고 리스트에 추가합니다
data.append(json.loads(line))
# JSON 객체의 리스트를 DataFrame으로 변환합니다
df = pd.DataFrame(data)
return df
async def check_json(response, output_path):
""" 이 함수는 네트워크에서 응답을 받았을 때 'listugcposts'가 포함된 응답을 처리합니다.
문자열을 json으로 변환하고 데이터를 얻습니다. """
if "listugcposts" in response.url:
content = await response.text()
content = content.split(")]}'\n")[1]
# JSON으로 문자열 구문 분석
data_raw = json.loads(content)
data_raw = data_raw[2]
def safe_extract(data, *path, default=None):
try:
for key in path:
data = data[key]
return data
except (IndexError, KeyError, TypeError):
return default
for i, element in enumerate(data_raw):
timestamp = data_raw[i][0][1][6]
if 'year' not in timestamp and 'years' not in timestamp:
data = {
'review': safe_extract(
data_raw, i, 0, 2, 15, 0, 0),
'rating': safe_extract(
data_raw, i, 0, 2, 0, 0),
'source': safe_extract(
data_raw, i, 0, 1, 13, 0),
'timestamp': safe_extract(
data_raw, i, 0, 1, 6),
'language': safe_extract(
data_raw, i, 0, 2, 14, 0),
}
# 중복을 피하기 위해 기존 데이터를 세트로로 로드합니다
existing_data = set()
if os.path.exists(output_path):
with open(output_path, 'r', encoding='utf-8') as file:
for line in file:
existing_data.add(line.strip())
new_data_json = json.dumps(
data, ensure_ascii=False)
if new_data_json not in existing_data:
# 새 데이터를 JSON 파일에 작성합니다
with open(output_path, 'a', encoding='utf-8') as file:
file.write(new_data_json + '\n')
async def main_google_reviews(search_input):
""" Google 리뷰를 스크랩하는 주요 함수입니다 """
# google의 주요 URL
url = (
"https://www.google.com/maps/@38.7156642,-9.1243907,16z?entry=ttu")
# 파일 경로
path = "data/reviews_google.json"
async with async_playwright() as pw:
# 크로미움 브라우저의 인스턴스를 만들고 실행하는 부분
browser =
<div class="content-ad"></div>
이 기사에서는 Google Maps 리뷰 및 평점, 타임스탬프 및 기타 중요한 요소를 웹 스크랩하는 기능 스크립트를 자세히 살펴보았습니다. 이 스크립트는 유료 API에 대한 비용 효과적인 대안을 제공하며 높은 속도와 성능을 자랑합니다. 가벼운 방식으로 HTML 파서가 필요 없어 손쉬운 해결책이 됩니다.
또한 Google Maps 리뷰의 다양한 응용 및 사용 사례를 탐색해보았는데, 이것들이 숙박업, 소매업, 여행업, 음식업 등 다양한 산업에 대한 잠재적 이점을 강조했습니다.
경쟁 우위를 확보하기 위해 Google Maps에서 데이터를 추출하는 것이 중요합니다. 다행히도 이 기사는 제공된 코드 예제를 따라 Google Maps 리뷰를 손쉽게 스크래핑할 수 있는 간단하고 무료한 해결책을 제공합니다.