
그래서 나는 시계열 모델에 관한 논문을 읽고 있었는데, 갑자기 “이게 뭐지?” 라는 부분에 닿았어. 이 모델은 하나의 예측 값만 내놓는 것이 아니라, 여러 예측값 범위를 생성했어. 내 머리는 바로 오버드라이브 상태로 전환되었어- 이걸 어떻게 평가해야 할지 말이지! 나는 주로 RMSE나 MAD 같은 명백한 지표들을 사용해왔는데, 실제 값과 예측 값 사이의 차이를 계산하는 것과 같거든. 그런데 이제 예측값은 여러 개의 숫자들이 있고, 그저 말하자면 내 머리가 터질 것 같았어 😅
그때 저자가 Weighted Quantile Loss를 소개했고, 나는 이에 깊이 이해하고 다른 사람들이 명확하게 이해할 수 있도록 이 가이드를 준비해야 한다고 생각했어.
이 글을 마치면, 이 지표를 어떻게 계산하는지와, 그것을 해석하는 방법을 정확히 알게 될 것이고, 무엇보다도 확신을 갖고 확률적 예측을 평가할 수 있을 거야.
이 글에서 설명한 결과를 재현하기 위한 코드는 해당 저장소에 있습니다.
Quantile Loss Formula
자, Quantile Loss의 공식부터 시작해봅시다:
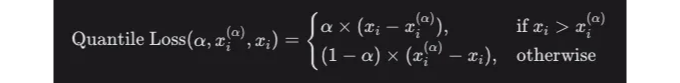
하지만 솔직히, 누가 수학에 시간을 할애할 수 있을까요? 실제로 의미 있는 방식으로 이것을 코드를 사용하여 분석해 보겠습니다!
먼저, 예측값과 실제 값에 대한 간단한 더미 데이터를 정의해보겠습니다. 여기서 예측값은 quantile α = 0.1일 때의 xᵢ(α)이며, 실제 값은 xᵢ입니다.
import numpy as np
prediction = np.array([1, 2, 3, 4, 5])
actual = np.array([10, 22, 30, 40, 51])
quantile = 0.1
이제 각 시간 단계 i에 대해 quantile α = 0.1에서의 예측값에 대한 quantile 손실을 계산해보겠습니다:
def quantile_loss(alpha, q, x):
return np.where(x > q, alpha * (x - q), (1 - alpha) * (q - x))
metrics = quantile_loss(quantile, prediction, actual)
print(metrics)
여기 이 코드가 하는 일에 대한 설명입니다:
- alpha, α,는 우리의 quantile을 나타냅니다(이 경우에는 0.1)
- q는 예측된 값들을 나타냅니다
- x는 실제 관측된 값들을 나타냅니다
np.where 함수는 실제 값이 예측된 값보다 큰지에 따라 적절한 공식을 적용하여 손실을 계산하는 데 도움을 줍니다.
더미 매개변수로 실행하면 아래와 같은 결과를 얻을 수 있어요:
# 출력: array([0.9, 2. , 2.7, 3.6, 4.6])
여기서 보고 계신 것은 α가 0.1일 때 각 예측값의 분위 손실입니다. 숫자는 선택한 분위에 따라 예측이 실제 값에 대해 얼마나 잘 수행되었는지 알려줍니다. 초과 추정과 미달 추정을 다르게 처벌합니다.
분위 손실 집계하기
실제로는 하나의 분위에 대한 분위 손실만 계산하는 것이 아닙니다. 실제 응용 프로그램에서는 종종 여러 분위에 걸쳐 확률적 예측을 생성해야 합니다. 그래서 모델의 확률적 예측에서 분위 손실을 집계하는 방법을 살펴보겠습니다.
이 더미 데이터 세트를 사용하여 계산 과정을 살펴보겠습니다:
data = {
"label": np.array([3, 5, 7]), # 실제 값
"0.5": np.array([3.0, 5.0, 7.0]), # 분위가 alpha = 0.5 일 때 모델의 예측
"0.1": np.array([2.5, 4.5, 6.5]), # 분위가 alpha = 0.1 일 때 모델의 예측
"0.9": np.array([3.5, 5.5, 7.5]), # 분위가 alpha = 0.9 일 때 모델의 예측
}
먼저 각 분위에 대한 분위 손실을 계산해보겠습니다:
quantiles = [0.1, 0.5, 0.9]
quantile_losses = {}
# 각 분위수별로 각 시간 단계에서 분위손실 계산
for quantile in quantiles:
ql = quantile_loss(quantile, prediction, actual)
quantile_losses[str(quantile)] = ql
print(f"{quantile}에 대한 분위손실: {ql}")
이를 실행하면 각 시간 단계(i = 1에서 3)에 대해 0.1, 0.5 및 0.9의 각 분위수에 대한 분위손실이 계산되고 결과가 출력됩니다:
# 출력:
# 0.1에 대한 분위손실: [0.05 0.05 0.05]
# 0.5에 대한 분위손실: [0. 0. 0.]
# 0.9에 대한 분위손실: [0.05 0.05 0.05]
이제 이러한 손실을 시간 단계별로 가중치를 적용하여 집계합니다. 가중치는 약간 이상할 수 있지만 걱정하지 마세요. 곧 중요성에 대해 자세히 알게 될 것입니다.
#각 분위수에 대해 가중치를 사용하여 시간 단계별로 집계합니다
집계된_qls = {}
가중치 = 2/np.abs(actual).sum()
for 분위수 in 분위수:
ql = quantile_losses[str(분위수)]
집계된_ql = np.sum(ql) * 가중치
집계된_qls[str(분위수)] = 집계된_ql
print(f"{분위수}에 대한 집계된 분위 손실: {집계된_ql}")
다음과 같은 일이 벌어집니다:
- 각 분위수에 대해 모든 시간 단계의 분위수 손실을 합산합니다.
- 그런 다음이 합계에 가중치를 곱합니다. 이 가중치는 실제 값의 크기를 기준으로 손실을 정규화하는 데 사용됩니다. 이는 다른 데이터 세트 간에 손실 값을 비교할 수 있게 도와줍니다.
결과는 다음과 같게 될 것입니다:
# 결과:
# 0.1에 대한 집계된 분위수 손실: 0.020000000000000004
# 0.5에 대한 집계된 분위수 손실: 0.0
# 0.9에 대한 집계된 분위수 손실: 0.019999999999999997
마지막으로 전체 지표를 얻으려면 이러한 집계된 손실 값을 단순 평균 내기만 하면 됩니다:
# 이제 간단한 평균을 내보겠습니다
단순_평균 = np.mean(list(aggregated_qls.values()))
print(f"단순 평균: {simple_average}")
위 코드에서, 우리는 집계된 분위수 손실을 모두 합하고 3으로 나누어줍니다 (3개의 분위수 값들인 0.1, 0.5 및 0.9를 계산했기 때문에). 그렇게 해서 다음과 같은 값을 구할 수 있습니다:
# 출력: 간단한 평균: 0.013333333333333334
그렇게 해서, 너는 가중 사분위수 손실 (WQL)을 계산했어!
사분위수 손실을 읽는 법
그래서, 우리는 어떻게 사분위수 손실을 계산하는지 살펴보았지만, 이게 정말 무엇을 의미하는 걸까? 보다 명확한 그림을 얻기 위해 아래 차트를 살펴보자. 이 차트는 다른 사분위수로 나타낸 손실값을 시각화했다:

차트 분석
이 차트에서는 참값 xᵢ 및 예측된 분위수 xᵢ(α) = 5에 따라 양자 손실이 어떻게 변하는지 볼 수 있습니다. 서로 다른 색상의 선은 세 가지 다른 분위수 수준 α = 0.1, α = 0.5 및 α = 0.9에서 양자 손실을 나타냅니다.
이제 이해해야 할 중요한 점은:
예측값과 실제 값이 같을 때 손실은 0입니다-놀랄 만한 일은 없네요! 둘 다 다를 때, 일이 흥미롭게 시작합니다.
분위수 α=0.9
우리가 α = 0.9에서 시작해보겠습니다. 실제 값이 8일 때(우리는 3만큼 과소 평가했습니다), 분위 손실은 2.7로 치솟습니다. 그러나 실제 값이 실제로 2일 때(3만큼 과대 평가한 것), 손실은 단지 0.3입니다. 왜 그럴까요?
우리가 0.9 분위수에서 예측을 할 때, 우리는 실제 값이 해당 숫자 아래에 있을 것이라고 90% 확신하는 것을 의미합니다. 그래서 실제 값이 더 높게 나오면, 우리의 모델이 정말 크게 엉망이라는 뜻이 되어 더 벌을 부과합니다. 양쪽 다 손실률이 직선적이지만 서로 다른 비율로 나타난다는 점에 주목하세요-과소평가할 때 더 가파르게 상승하며, 이는 높은 분위에서 예상하는 것과 일치합니다.
분위수 α=0.1
자, 이제 α = 0.1로 뒤집어 놓겠습니다. 이것은 반대 방향에서 흥미로워지는 부분입니다. 실제 값이 8인 경우 (우리가 3만큼 과소평가한 경우), 손실은 단지 0.3입니다. 그러나 실제 값이 2인 경우 (우리가 3만큼 초과평가한 경우), 손실은 2.7로 뛰어올라갑니다. α = 0.1에서 이런 일이 일어나는 이유는 우리가 실제 값이 우리의 예측보다 낮을 가능성이 단지 10% 라고 말하기 때문입니다. 실제로 값이 예측보다 낮다면, 그것은 큰 오류이며, 모델이 더 큰 타격을 입게 됩니다.
분위수 α=0.5
마지막으로, α = 0.5에 대해 이야기해 봅시다. 이것은 중앙에 정확히 위치한 값이기 때문에 특별합니다 - 중앙값입니다. 여기서 초과평가와 과소평가에 대한 손실은 완벽하게 대칭적입니다. 차트를 보면, 너무 높게 예측하든 너무 낮게 예측하든 손실이 똑같은 속도로 증가하는 것을 볼 수 있습니다. 이것은 α = 0.5에서의 분위수 손실이 사실 평균 절대 편차(Mean Absolute Deviation, MAD) 손실의 확장된 버전에 불과하기 때문입니다.
이 공식은 어떻게 단순화될까요? 확인해보세요:
α = 0.5 일 때:
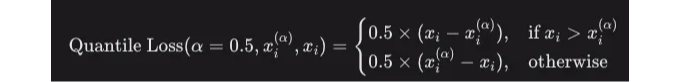
이를 다음과 같이 단순화할 수 있습니다:
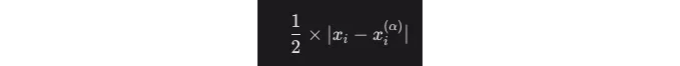
MAD 손실의 정확히 절반에 해당합니다. 따라서 α = 0.5일 때, 분위 손실은 MAD의 스케일 버전(스케일링 요인이 0.5인)으로 오류를 양쪽 모두 동일하게 벌칙합니다.
모든 것을 가중 분위손실로 연결하기
분위 손실은 예측 값과 실제 값 사이의 오류를 측정하는 메트릭으로 볼 수 있습니다. 벌점은 오류가 과소 또는 과대 추정인지, 모델이 얼마나 확신을 가졌는지에 따라 달라집니다. 이때 더 높은 분위는 더 많은 확신을 나타냅니다.
이 손실을 집계하면(이전에 했던 것처럼), 모형의 성능을 더 세밀하게 이해할 수 있습니다. 단일 정확도 지표에 의존하는 대신, 여러 가지 시나리오에 걸쳐 모형의 오류가 어떻게 분산되어 있는지에 대한 포괄적 요약을 얻을 수 있습니다. 이 방법은 서로 다른 모형의 성능을 비교하기 위한 단일 숫자가 필요할 때 귀중합니다.
예측 품질과 가중 분위 손실 간의 관계
이론을 다룬 이제, 서로 다른 예측 품질이 WQL에 어떻게 영향을 미치는지를 알아보겠습니다. 총 세 가지 주요 시나리오인 과대 추정, 과소 추정 및 정확한 예측을 고려하여 WQL을 살펴봅니다. 각각을 살펴보고, 어떻게 WQL에 영향을 주는지 살펴보겠습니다.
과대 추정 시나리오
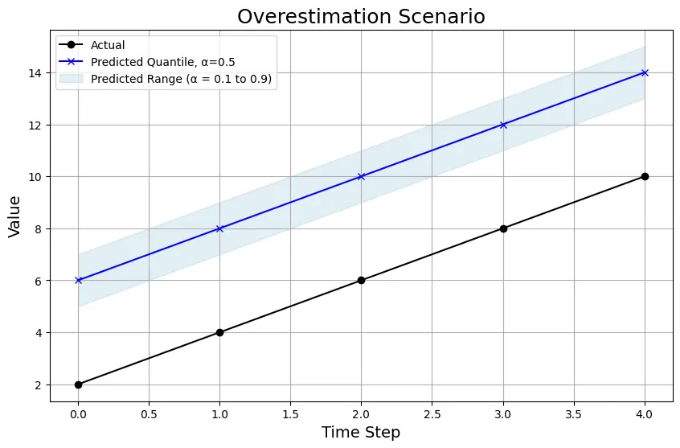
과대평가 시나리오에서 모델의 예측값은 일관되게 실제 값보다 높습니다:
- 차트 분석: 0.5 백분위 예측(파란색 선)이 실제 값(검은색 선)보다 훨씬 높을 뿐만 아니라, 0.1 및 0.9 백분위 예측도 오버슈팅중입니다(그림자 영역에서 확인 가능). 이는 모델이 전반적으로 너무 낙관적이라는 것을 보여줍니다.
- WQL: 이 시나리오에서의 WQL은 0.58입니다.
과소평가 시나리오
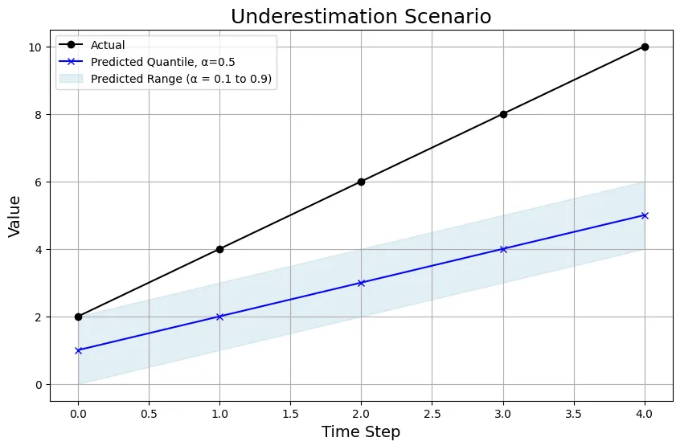
"워런다"는 시나리오에서, 모델은 일관되게 실제 값보다 낮은 값을 예측합니다:
- 차트 분석: 여기서, 0.5 백분위에서의 예측값(파란선)이 실제 값보다 낮고, 전반적인 예측 범위(음영 영역)도 낮습니다. 그러나 절대 오류는 과대 예측 시나리오보다 심하지 않습니다.
- WQL: 이 시나리오에서의 WQL은 0.41로, 나쁜 모델을 나타냅니다. 그러나 과대 예측 시나리오만큼 나쁘지 않습니다.
정확한 예측 시나리오
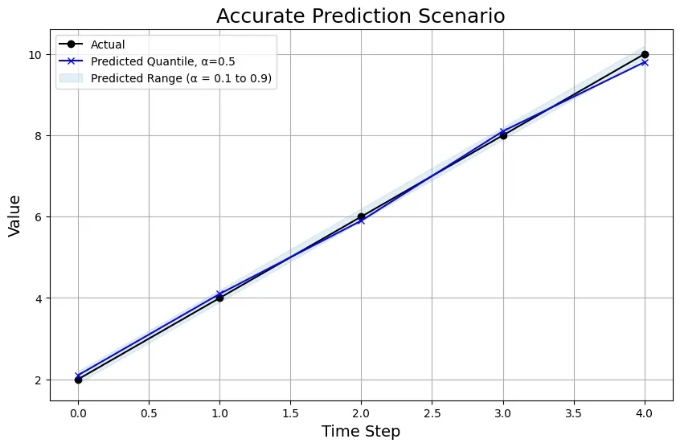
정확한 예측 시나리오에서는 모델의 예측이 실제 값과 근접합니다:
- 차트 분석: 0.5 분위수 예측이 실제 값과 매우 가깝고, 예측 범위가 좁아지면서 모델이 예측에 대해 매우 자신 있음을 보여줍니다.
- WQL: 예측 범위가 매우 정확하며 초점이 맞다면, WQL은 0.01에서 사실상 제로입니다.
결론
이 게시물에서는 Weighted Quantile Loss (WQL)의 내부와 외부를 탐색했습니다. 수식을 이해하고 다양한 예측 시나리오에서 해석하는 방법까지 알아보았습니다. WQL은 모델의 성능을 이해하는 실용적인 방법을 제공하는데, 단순히 점 추정이 아닌 예측 분포를 출력할 수 있다면 이를 이용할 수 있습니다.
확률적 예측을 평가하는 데 어떤 어려움을 겪었나요? 의견이나 질문을 댓글로 공유해주세요!