
UIUC 대학원생으로서 최근 대학으로부터 받은 이메일 중에서 최신 CrowdStrike 업데이트에 대해 알림을 받았습니다. 메일을 스크롤하다가, 대량 이메일 아카이브로 이어지는 링크를 발견했습니다. 호기심에 휩쓸려 더 깊이 파고들어, 1999년 10월 22일부터 2011년 11월 20일까지 CITES Massmail 시스템을 통해 유포된 과거 대학 이메일을 발굴해냈습니다.
이 발견으로 분석적 호기심이 불타오르기 시작했습니다: 몇 년 동안 어떤 주제가 다뤄졌을까요? 경보 이메일의 유형에서 패턴이나 추세가 있을 수 있을까요?
밑바닥부터 파고들어 알아내야 한다는 생각이 들었습니다.
이메일에서 의미 있는 통찰을 발견하기 위해 이러한 질문에 대답하고자, SAS Visual Text Analytics의 강력함을 고려하여 SAS Viya를 사용하기로 결정했습니다. 그러나 실제 분석에 착수하기 전에 먼저 할 일은 웹 사이트에서 이메일 데이터를 스크레이핑하고 전처리하는 것입니다.
Bs4를 사용한 스크레이퍼 구축
Beautifulsoup4은 주로 HTML이나 XML 파일에서 데이터를 추출하는 데 사용되는 Python 라이브러리입니다.
위 라이브러리를 사용하여 이메일을 스크레이핑하는 파이썬 스크립트 massmail_scraper.py를 작성할 것입니다. 스크립트는 스크레이핑한 데이터를 저장하기 위한 csv 파일 massmail_system.csv을 생성하는 것부터 시작합니다.
이제 스크래핑 프로세스 자체로 넘어와봅시다. Massmail 웹사이트로 이동하면 메일 레코드가 테이블에 저장됩니다. 각 메일 세부정보는 tr (테이블 행) 태그에 저장되어 있습니다.

메일 태그 번호, 제목 및 발송 날짜를 추출하는 과정은 a (앵커) 태그, 왼쪽에 정렬된 td (테이블 데이터) 태그 및 오른쪽에 정렬된 td 태그를 찾아서 수행됩니다.
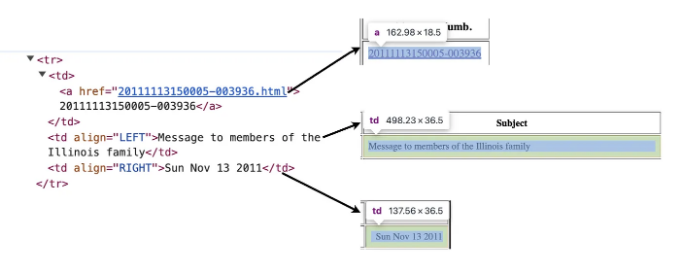
table_rows = soup.find_all('tr')
for tr in table_rows[1:]:
mail_no_a_tag = tr.find('a') or 'No Mail Tag'
mail_no = mail_no_a_tag.get_text() or 'No Mail Content'
mail_desc, mail_content = mail_content_extract(mail_no_a_tag['href'])
subject = tr.find(lambda tag: tag.name == 'td' and tag.get('align') == 'LEFT').get_text() or 'No Subject'
date = tr.find(lambda tag: tag.name == 'td' and tag.get('align') == 'RIGHT').get_text() or 'Unknown Date'
mail_records.append([date, mail_no, mail_desc, mail_content, subject])
스크립트가 개별 메일 레코드의 HTML 페이지로 이동한 후에, 우리는 b 태그를 사용하여 헤더를 추출하고, xmp 태그를 사용하여 메일 내용을 추출합니다.
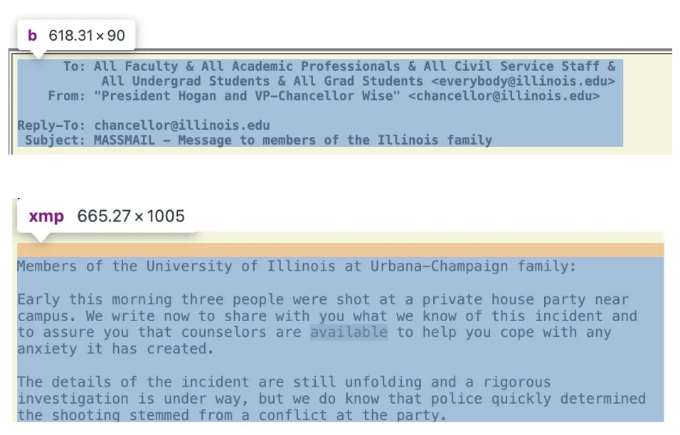
def mail_content_extract(link):
"""
메일의 헤더와 내용을 추출합니다.
Args:
link (str): 메일의 개별 HTML 링크
Returns:
mail_desc (str): 메일의 헤더
mail_content (str): 메일의 내용
"""
response = requests.get("https://massmail.illinois.edu/citesMassmailArchive/" + str(link))
page_content = response.content
individual_page_soup = BeautifulSoup(page_content, 'html.parser')
mail_content = individual_page_soup.find('xmp').get_text() or '내용 없음'
mail_desc = individual_page_soup.find('b').get_text() or '헤더 없음'
return mail_desc, mail_content
노트: 항상 유효하지 않은 값이 나올 수 있으므로 그 사실을 염두에 두고 값을 반환하지 않을 경우 대체 값이 있어야 합니다.
텍스트 전처리
이 프로젝트에서는 mail_preprocessing.py를 사용하여 두 가지 주요 전처리 단계에 중점을 두겠습니다. 첫 번째로 각 레코드에서 날짜를 추출하고 해당 날짜를 연도, 월, 일 및 요일로 분해하는 데 아래 함수를 사용합니다:
def convert_date(date_str):
"""
주어진 날짜 문자열에서 날짜 세부 정보를 추출합니다.
Args:
date_str (str): 입력 메일 텍스트
Returns:
year (str): 추출된 연도
month (str): 추출된 월
day (str): 추출된 일
day_name (str): 추출된 요일
"""
try:
date_obj = datetime.strptime(date_str, '%a %b %d %Y').date()
year = date_obj.strftime('%Y')
month = date_obj.strftime('%b')
day = date_obj.strftime('%d')
day_name = date_obj.strftime('%A')
return year, month, day, day_name
except ValueError:
return "Unknown Year", "Unknown Month", "Unknown Day", "Unknown Day of Week"
이메일의 제목과 본문에는 텍스트를 소문자로 변환하고, 구두점을 제거하고, 숫자를 제거하고, 이메일 주소나 웹 링크를 제거하며, 추가 공백을 제거하기 위해 전처리해야 합니다. 이 작업은 아래 함수를 사용하여 수행되었습니다:
def mail_content_processing(text):
"""
주어진 텍스트 입력을 전처리합니다.
Args:
text (str): 입력 이메일 텍스트
Returns:
processed_text (str): 전처리 후의 텍스트
"""
try:
if text is None:
return "Empty Content"
processed_text = text.lower()
processed_text = re.sub(r'[^\w\s]', '', processed_text)
processed_text = re.sub(r'\d+', '', processed_text)
processed_text = re.sub(r'http\S+|www\S+|@\S+', '', processed_text)
processed_text = ' '.join(processed_text.split())
return processed_text
except Exception as e:
return "String Error"

이로써 시리즈의 첫 번째 부분이 마무리되었습니다. 두 번째 부분에서는 SAS Viya를 사용하여 처리된 데이터를 활용하여 텍스트 분석 파이프라인을 실행하고 Visual Analytics를 사용하여 시계열 대시보드를 작성하는 방법을 보다 심층적으로 살펴볼 것입니다.
"다음 부분은 여기에서 확인하세요: "